Code
# !pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2 ![]()
“La percepción no es un fragmento de un solo sentido, sino una sinfonía en la que todos los sentidos se fusionan armónicamente.”, James Gibson, fundador de la ecopsicología.
Durante mucho tiempo en la historia de la inteligencia artificial, hubo un desafío difícil de resolver: el “multimodalidad”. Los humanos utilizamos simultáneamente varios sentidos (modalidades) como vista, audición y tacto para percibir el mundo, e integramos estos sentidos de manera orgánica. Por ejemplo, cuando bebemos café en un café, recibimos información diversa simultáneamente: el calor de la taza de café (tacto), el aroma del café (olfato), las conversaciones de las personas a nuestro alrededor (audición) y el paisaje interior del café (vista). A través de esta información, formamos una experiencia holística de estar en un café.
Sin embargo, los primeros modelos de inteligencia artificial tuvieron dificultades para procesar esta información multimodal. Las investigaciones en IA, que comenzaron a mediados de la década de 1950, se centraron principalmente en el procesamiento de una sola modalidad (texto, imagen, voz). Aunque hubo logros notables en cada campo, como traducción y reconocimiento de voz, integrar estos para comprender como lo hace un humano era un problema de otra dimensión.
En este capítulo, exploraremos a fondo las teorías fundamentales del aprendizaje profundo multimodal y las arquitecturas que han sobrevivido. Examinaremos cómo cada arquitectura ha extendido y evolucionado el ADN del aprendizaje profundo, y cómo contribuyen a resolver problemas complejos del mundo real.
Desafío: ¿Cómo integrar y procesar datos de diferentes formas, como texto, imagen y audio, en un solo modelo? Estos datos tienen formas de representación, dimensiones y características estadísticas diferentes. ¿Cómo fusionar información heterogénea para aprender una representación significativa?
Agonía del investigador: Los investigadores necesitaban encontrar nuevos métodos que pudieran modelar eficazmente la interacción entre las modalidades mientras mantenían sus características únicas, es decir, un nuevo ADN del aprendizaje profundo. Se requería una verdadera fusión más allá de una simple concatenación, donde cada modalidad comprendiera el contexto de las otras y proporcionara información complementaria.
Los datos multimodales se refieren a la combinación de dos o más formas diferentes de datos, como texto, imagen, audio y video. Por ejemplo, un artículo de noticias puede estar compuesto por texto e imágenes, mientras que una película está formada por video y audio. Los humanos integran naturalmente esta información multimodal; entender el entorno a través del tacto, oler y escuchar es algo completamente normal para nosotros.
¿Por qué el aprendizaje profundo multimodal fue un problema difícil?
Representación de datos heterogéneos: El texto, las imágenes y los audios tienen formas de representación, dimensiones y características estadísticas diferentes. Integrar y procesar eficazmente estos datos heterogéneos en un solo modelo ha sido un desafío.
Complejidad de la fusión de información: La simple concatenación de la información de cada modalidad no es una verdadera fusión. Se requiere modelar interacciones complejas, donde cada modalidad comprende el contexto de las otras, proporciona información complementaria y a veces armoniza información contradictoria.
Escasez e imbalance de datos: Los datos multimodales son relativamente escasos en comparación con los datos de una sola modalidad, y también existe un problema de desequilibrio entre las diferentes modalidades. Por ejemplo, hay más datos compuestos por imágenes y texto que datos que incluyen imágenes, texto y audio.
A pesar de estos desafíos, el aprendizaje profundo ha ofrecido nuevas posibilidades para el procesamiento de datos multimodales. Después de la década de 2010, el desarrollo de las tecnologías de aprendizaje profundo, especialmente la arquitectura del Transformer, jugó un papel decisivo en el avance del aprendizaje profundo multimodal. Esto fue un punto de inflexión crucial en el ADN del aprendizaje profundo. El mecanismo de autoatención (self-attention) del Transformer permitió modelar eficazmente no solo las relaciones entre los elementos dentro de cada modalidad, sino también las interacciones complejas entre diferentes modalidades. Hasta entonces, las CNN se habían especializado en el procesamiento de imágenes y las RNN en el procesamiento de datos secuenciales, mientras que el Transformer proporcionó una arquitectura versátil (universal) con la flexibilidad de aplicarse a diversas modalidades.
El aprendizaje profundo multimodal es una tecnología crucial para que la inteligencia artificial pueda entender e interactuar con el mundo como lo hace un ser humano. Va más allá de simplemente procesar diferentes formas de datos, conectando orgánicamente los significados contenidos en cada dato para permitir inferencias más ricas y precisas. Al igual que varias áreas del cerebro colaboran para realizar funciones cognitivas complejas, el aprendizaje profundo multimodal es una fuerza impulsora clave para elevar la inteligencia artificial a un nivel superior.
Áreas de aplicación principales
Respuesta a consultas visuales (Visual Question Answering, VQA): Genera respuestas a preguntas basadas en una imagen y una pregunta (texto). Va más allá del simple reconocimiento de objetos en la imagen, requiriendo una comprensión integral del significado de la imagen y la pregunta. Por ejemplo, para responder a “¿De qué color es el sombrero que lleva el hombre en la imagen?”, se necesita un proceso complejo que incluye encontrar al hombre, reconocer el sombrero y determinar su color.
Generación de descripciones de imágenes (Image Captioning): Genera automáticamente texto para describir una imagen. Requiere comprender con precisión el contenido de la imagen y expresarlo en oraciones naturales.
Análisis de sentimientos multimodal (Multimodal Sentiment Analysis): Determina los sentimientos del usuario combinando información como texto, voz y expresiones faciales. Puede detectar tonos irónicos o sutiles cambios emocionales a través de variaciones en el tono de voz o expresiones faciales que pueden ser difíciles de captar solo con texto.
Conducción autónoma: Integra datos de varios sensores, como cámaras (imágenes), LiDAR (sensores 3D), GPS (información de ubicación) y radares para reconocer el entorno circundante y tomar decisiones de conducción. Cada sensor proporciona información diferente, y su análisis integrado es necesario para una conducción precisa.
Manejo robótico: Para manipular objetos, un robot debe comprender la posición y forma del objeto visualmente y ajustar la fuerza adecuada basándose en la información táctil obtenida al agarrar el objeto.
Diagnóstico médico: Combina datos de diversas fuentes, como radiografías, MRI (imágenes), registros médicos (texto), señales biológicas (datos de series temporales) y información genética para diagnosticar y predecir enfermedades. Cada conjunto de datos proporciona pistas diferentes sobre la enfermedad, y su análisis integrado es esencial para un diagnóstico preciso.
La investigación en aprendizaje profundo multimodal es un viaje fascinante que muestra la evolución del ADN del aprendizaje profundo. Este viaje se puede dividir en las siguientes etapas principales.
A principios de la década de 2010, las investigaciones iniciales en aprendizaje profundo multimodal se centraron principalmente en la generación de descripciones de imágenes (image captioning) y VQA (Visual Question Answering). En esta época, los modelos basados en CNN-RNN predominaban, utilizando CNNs (Redes Neuronales Convolucionales) para extraer características de las imágenes y RNNs (Redes Neuronales Recurrentes) para procesar el texto. Las CNNs eran efectivas para capturar características espaciales en las imágenes, mientras que las RNNs eran fuertes en el procesamiento de información secuencial del texto. Sin embargo, los modelos iniciales solían utilizar principalmente el enfoque de fusión tardía (late fusion), que procesa cada modalidad de forma independiente y luego combina los resultados en la última etapa. Aunque este método tenía la ventaja de preservar las características únicas de cada modalidad, también tenía la limitación de no poder reflejar adecuadamente la interacción entre modalidades en las fases iniciales.
Entre los modelos representativos de esta época están DeViSE (Frome et al., 2013), que proyecta imágenes y embeddings de palabras en el mismo espacio para calcular la similitud entre imagen y texto, y m-RNN (Mao et al., 2014), que combina CNN y RNN para generar descripciones de imágenes y añade una capa multimodal para integrar información de diferentes modalidades.
A mediados de la década de 2010, la aparición del mecanismo de atención (attention mechanism) marcó un punto de inflexión importante en la investigación de deep learning multimodal. Este mecanismo permitió modelar más precisamente la relevancia entre imágenes y texto. Por ejemplo, en el caso de la generación de descripciones de imágenes, la atención permitía aprender qué regiones de la imagen “atender” al generar una palabra específica, y en VQA (Preguntas y Respuestas Visuales), ayudaba a determinar qué partes de la imagen observar para responder a una pregunta.
La introducción del mecanismo de atención mejoró significativamente el rendimiento de los modelos de generación de descripciones de imágenes y VQA. Algunos modelos representativos incluyen Show, Attend and Tell (Xu et al., 2015), que introduce la atención en la generación de descripciones de imágenes para centrarse en las regiones de la imagen relevantes a las palabras generadas, y Stacked Attention Networks (Yang et al., 2016), que aplica múltiples capas de atención a la imagen para generar respuestas a preguntas en VQA.
En 2017, con la introducción de la arquitectura del Transformer en el artículo “Attention is All You Need”, el deep learning multimodal entró en una nueva fase. El Transformer tiene la ventaja de poder modelar directamente las relaciones entre todos los elementos de una secuencia de entrada basándose en el mecanismo de autoatención (self-attention).
ViT (Vision Transformer, 2020): ViT divide las imágenes en parches (patches) y los introduce en un Transformer. ViT se convirtió en una alternativa potente a las CNN en el procesamiento de imágenes, mostrando un rendimiento excepcional en tareas como la clasificación de imágenes al modelar eficazmente las dependencias de largo alcance dentro de las imágenes.
CLIP (Contrastive Language-Image Pre-training, 2021): CLIP aprende a embeber imágenes y texto en el mismo espacio utilizando grandes conjuntos de datos de pares imagen-texto. Esto permitió lograr resultados revolucionarios en diversas tareas downstream, como la clasificación de imágenes y la detección de objetos, con un rendimiento sobresaliente sin necesidad de fine-tuning adicional.
DALL-E (2021), Imagen (2022), Stable Diffusion (2022): Los modelos que generan imágenes de alta calidad a partir de descripciones de texto demostraron las sorprendentes capacidades de los modelos generativos basados en Transformers. Estos modelos aprenden relaciones complejas entre texto e imágenes, produciendo resultados de generación de imágenes a un nivel que era difícil de imaginar anteriormente.
GPT-4V (2023), Gemini (2023): La aparición de modelos multimodales a gran escala (LMM, Large Multimodal Model) capaces de comprender y procesar texto e imágenes simultáneamente ha abierto nuevas posibilidades en el aprendizaje profundo multimodal. Estos enormes modelos con miles de millones de parámetros han logrado un rendimiento a nivel humano en diversas tareas multimodales, ubicándose en la vanguardia de la investigación de inteligencia artificial.
La investigación reciente en aprendizaje profundo multimodal ha evolucionado más allá de la simple fusión de información, hacia el desarrollo de la capacidad de generar e inferir nuevo conocimiento basándose en las diferentes modalidades.
Desarrollo del LMM (Large Multimodal Model): Están surgiendo continuamente LMMs que integran más modalidades (audio, video, datos de sensores 3D, etc.) y poseen habilidades de inferencia más complejas.
Investigación sobre técnicas eficientes de fusión: Por otro lado, también se está realizando una investigación activa en técnicas de fusión eficiente que maximicen el efecto de la integración de información mientras reducen los costos computacionales para utilizar eficazmente los modelos multimodales con recursos informáticos limitados.
Explicabilidad (XAI) y problemas éticos: A medida que aumenta la complejidad de los modelos multimodales, también crece la importancia de la investigación dirigida a comprender el proceso de toma de decisiones del modelo y abordar cuestiones éticas como sesgos.
En la siguiente sección examinaremos con más detalle los enfoques iniciales en el aprendizaje profundo multimodal, así como las principales arquitecturas que han “sobrevivido” durante este proceso.
Como se vio en la Sección 10.1.3, las transformer y CLIP han traído una innovación a la aprendizaje profundo multimodal. Sin embargo, este progreso no se logró de un día para otro. Antes de esto, ya existían numerosos intentos de combinar imágenes y texto, e incluso distintas modalidades, y estos estudios iniciales sentaron las bases sólidas del aprendizaje profundo multimodal moderno. En esta sección, examinaremos los enfoques clave y su significado que lideraron el amanecer de la investigación multimodal basada en aprendizaje profundo a principios y mediados de la década de 2010.
La generación de descripciones de imágenes (Image Captioning) es una tarea que consiste en generar automáticamente oraciones de lenguaje natural (descripciones) para describir una imagen dada. Esta es una problemática multimodal típica que convierte información visual (imágenes) en información lingüística (texto), y fue el principal objeto de estudio en los inicios de la investigación multimodal basada en aprendizaje profundo. La generación de descripciones de imágenes se asemeja a un niño que mira un libro de cuentos y dice: “¡Aquí hay un perro, y allá hay una pelota!”.
En los inicios de la investigación en generación de descripciones de imágenes, los modelos combinados de CNN y RNN predominaron. Era similar a conectar dos hemisferios cerebrales dentro del cerebro del aprendizaje profundo: un hemisferio visual gestionado por CNN y otro lingüístico gestionado por RNN. La CNN actuaba como codificador de imagen, utilizando redes como VGGNet o AlexNet para extraer vectores de características de la imagen, mientras que el RNN funcionaba como decodificador de texto, usando modelos como LSTM para generar oraciones de descripción basadas en los vectores de características de la imagen.
Un modelo representativo es Show and Tell (Vinyals et al., 2015), que propuso un método end-to-end que introduce las características de la imagen extraídas por CNN como el estado inicial oculto del LSTM para generar descripciones. Sin embargo, esta estructura CNN-RNN capturaba bien el contenido general de la imagen, pero tenía limitaciones en modelar claramente la relación entre áreas específicas de la imagen y palabras particulares del texto.
El mecanismo de atención, que “presta atención” a regiones específicas de la imagen, mejoró significativamente el rendimiento de los modelos de generación de descripciones de imágenes. El mecanismo de atención funciona similar a cómo nuestra vista naturalmente se dirige hacia las partes más importantes al apreciar una pintura.
Existen dos tipos principales de mecanismos de atención: Soft Attention y Hard Attention. Show, Attend and Tell (Xu et al., 2015) fue el primer modelo en introducir el mecanismo de Soft Attention a la generación de descripciones de imágenes, aprendiendo a qué región de la imagen prestar atención para generar cada palabra de la descripción, lo que permitió crear descripciones más precisas y detalladas.
A partir de 2017, surgió el enfoque Bottom-Up and Top-Down Attention, que combina información contextual general (top-down) con información sobre objetos individuales (bottom-up). El enfoque bottom-up utiliza modelos de detección de objetos como Faster R-CNN para identificar los objetos principales dentro de una imagen, mientras que el enfoque top-down calcula pesos de atención basados en estas características de objeto durante el proceso de generación de descripciones.
El modelo Bottom-Up and Top-Down Attention (Anderson et al., 2018) combinó ambos enfoques para mejorar significativamente el rendimiento en la generación de descripciones de imágenes. Esto es similar a considerar el flujo general de una historia mientras se describe detalladamente los objetos presentes en cada escena.
La investigación en captioning de imágenes ha añadido elementos importantes al ADN del aprendizaje profundo. La combinación CNN-RNN presentó un marco fundamental para combinar eficazmente diferentes modalidades, y el mecanismo de atención se consolidó como una tecnología clave en el aprendizaje multimodal profundo. Además, la Atención Bottom-Up and Top-Down elevó un paso más la capacidad de comprensión de imágenes de los modelos de aprendizaje profundo.
Estos avances no solo han impulsado el captioning de imágenes, sino que también sentaron las bases para su posterior expansión a diversas tareas multimodales, como VQA y traducción multimodal. Recientemente, han surgido modelos basados en transformadores, como BLIP, que están demostrando un buen rendimiento no solo en el captioning de imágenes, sino también en una variedad de tareas multimodales.
BLIP (Bootstrapping Language-Image Pre-training) es un modelo basado en transformadores para el captioning de imágenes. BLIP se pre-entrena conjuntamente con imágenes y texto, lo que permite un buen rendimiento no solo en el captioning de imágenes sino también en tareas multimodales como VQA y búsqueda de imagen-texto.
A continuación se muestra un ejemplo de código para generar captions de imágenes utilizando el modelo BLIP a través de la biblioteca Hugging Face Transformers.
# !pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
import requests
import matplotlib.pyplot as plt
# Load the model and processor
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# Download the image
url = "http://images.cocodataset.org/val2017/000000000632.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# Display the image
plt.imshow(image)
plt.axis('off')
plt.show()
# Preprocess the input
inputs = processor(image, return_tensors="pt")
# Generate the caption
outputs = model.generate(**inputs)
# Decode and print the caption
caption = processor.decode(outputs[0], skip_special_tokens=True)
print("Generated caption:", caption)
Generated caption: a bedroom with a bed and a windowPregunta y Respuesta Visual (Visual Question Answering, VQA) es una tarea en la que se proporciona una imagen y una pregunta formulada en lenguaje natural, y se genera una respuesta a dicha pregunta basándose en el contenido de la imagen. Si bien la generación de descripciones de imágenes consiste en “describir” el contenido de las imágenes, VQA implica hacer “preguntas y respuestas” sobre la imagen. Por ejemplo, responder a preguntas como “¿Qué está comiendo el gato?”. VQA requiere una comprensión más compleja y de mayor nivel de las imágenes en comparación con la generación de descripciones de imágenes, especialmente la capacidad de captar y razonar sobre la relación entre la imagen y la pregunta (texto).
Al igual que en la generación de descripciones de imágenes, los primeros modelos de VQA utilizaban una estructura combinada de CNN y RNN. Se extraían características de la imagen utilizando un CNN, se codificaba la pregunta con un RNN y luego se combinaban estas dos características para generar una respuesta. Sin embargo, simplemente combinar las características de la imagen y la pregunta no era suficiente para responder preguntas complejas.
Tras el éxito de los mecanismos de atención en la generación de descripciones de imágenes, estos fueron incorporados a VQA. El Co-Attention aplica atención tanto a la imagen como a la pregunta, calculando la relevancia entre cada palabra de la pregunta y cada región de la imagen. Esto permite encontrar de manera más precisa las regiones de la imagen relacionadas con la pregunta.
El Stacked Attention repite el proceso de atención varias veces para capturar gradualmente las relaciones complejas entre la imagen y la pregunta. Es como si un detective revisara una foto varias veces, profundizando gradualmente en su comprensión de la relación con la pregunta.
Entre los modelos representativos se encuentran Stacked Attention Networks (SAN) (Yang et al., 2016) y Dual Attention Networks (DAN) (Nam et al., 2017). SAN es un modelo que aplica múltiples capas de atención a la imagen para generar una respuesta a la pregunta, mientras que DAN calcula la atención por separado para la imagen y la pregunta, y luego combina estos resultados para generar la respuesta.
La mayor diferencia entre la generación de descripciones de imágenes y VQA es la integración de conocimiento externo. Para mejorar aún más las capacidades de inferencia de los modelos de VQA, se han realizado investigaciones para utilizar el conocimiento externo (conocimientos comunes, enciclopedias, etc.). El Knowledge Base (KB) utiliza bases de datos estructuradas como Wikipedia y ConceptNet para proporcionar la información necesaria para encontrar respuestas a las preguntas.
Las Redes de Memoria integran el conocimiento externo en forma de memoria, buscando y utilizando la información relevante de la memoria según la pregunta. Sin embargo, utilizar eficazmente el conocimiento externo sigue siendo un desafío importante debido a la incompletitud del conocimiento, la evaluación de la relevancia con respecto a la pregunta y la complejidad del proceso de inferencia.
La investigación en VQA ha añadido genes importantes al ADN del aprendizaje profundo. La combinación CNN-RNN proporciona una estructura básica para combinar imágenes y texto, compartida con la generación de descripciones de imágenes. El multimodal attention otorga a los modelos de aprendizaje profundo la capacidad de modelar relaciones complejas entre imagen y pregunta, lo que significa que estos modelos no solo combinan información, sino que también comprenden las interacciones entre diferentes tipos de información y pueden realizar inferencias.
La integración de conocimiento externo ha abierto la posibilidad de que los modelos de aprendizaje profundo realicen inferencias de mayor nivel utilizando el conocimiento y la experiencia humanos, en lugar de depender únicamente de los datos. 10.2.1 y 10.2.2 analizaron el captioning de imágenes y VQA, que fueron dos pilares fundamentales en las primeras investigaciones de aprendizaje profundo multimodal. Estos estudios contribuyeron significativamente a aplicar y desarrollar tecnologías clave del aprendizaje profundo como CNN, RNN y mecanismos de atención a problemas multimodales, y sentaron las bases para el surgimiento de modelos multimodales más potentes basados en transformadores (como CLIP, DALL-E, GPT-4V, Gemini, etc.).
Recientemente, han surgido modelos VQA basados en transformadores como ViLT (Vision-and-Language Transformer), que están demostrando un buen rendimiento. ViLT introduce parches de imagen y tokens de texto en el mismo modelo de transformador para modelar eficazmente las complejas interacciones entre imágenes y texto.
ViLT (Vision-and-Language Transformer) es uno de los modelos VQA basados en transformadores más destacados. ViLT introduce parches de imagen y tokens de texto en el mismo modelo de transformador para modelar eficazmente las complejas interacciones entre imágenes y texto.
A continuación se presenta un ejemplo de código para realizar VQA utilizando el modelo ViLT con la biblioteca Transformers de Hugging Face.
from transformers import ViltProcessor, ViltForQuestionAnswering
from PIL import Image
import requests
import matplotlib.pyplot as plt
# 모델과 프로세서 로드
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
model = ViltForQuestionAnswering.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
# 이미지 다운로드
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# 이미지 출력
plt.imshow(image)
plt.axis('off') # 축 제거
plt.show()
# 질문 설정
question = "How many cats are in the image?"
print("Question:", question)
# 입력 전처리
encoding = processor(image, question, return_tensors="pt")
# 추론
outputs = model(**encoding)
logits = outputs.logits
idx = logits.argmax(-1).item()
print("Predicted answer:", model.config.id2label[idx])
Question: How many cats are in the image?
Predicted answer: 2Supongamos que tenemos dos tipos de información: imágenes y texto. ¿Cómo podemos combinar esta información? El método más sencillo es agregar el vector de texto al final del vector de imagen para crear un nuevo vector. Este proceso de conectar información de fuentes de datos heterogéneas se denomina fusión (fusion). La capacidad de fusionar eficientemente la información de dos características de datos heterogéneas es fundamental en multimodalidad. Una de las razones por las que es difícil iniciar el aprendizaje profundo multimodal es porque es un campo que se está desarrollando muy rápidamente y carece de una sistematización adecuada.
En esta sección, nos basaremos en la clasificación propuesta en el curso de Multimodal Machine Learning de Carnegie Mellon University (CMU) para dividir la fusión multimodal en tres categorías principales. Aunque esta clasificación no es estándar en las investigaciones actuales de multimodalidad, es muy útil para entender sistemáticamente las diversas técnicas de fusión.
Las representaciones conjuntas son un método que representa los datos de múltiples modalidades en un espacio vectorial común (vector space). Es como si dibujáramos el texto y la imagen juntos en un solo lienzo.
En lugar de procesar los datos de cada modalidad por separado, se fusionan en un único vector de características integradas. Este vector encapsula la información de las modalidades. De esta manera, el modelo puede aprender las relaciones profundas entre las diferentes modalidades. Se puede manejar múltiples modalidades con un solo modelo. Además, al comprimir la información de varias modalidades en un solo vector, la estructura del modelo es relativamente simple y eficiente. Sin embargo, las características únicas de cada modalidad pueden diluirse o perderse durante el proceso de fusión. Si una modalidad contiene significativamente más información que otra, puede surgir un problema de desequilibrio de información. Y fusionar los datos de diferentes modalidades en un vector significativo es un problema muy difícil.
El método más simple es concatenar (concatenate) los vectores de características de cada modalidad. Además, el Modelo de Factorización Multimodal (Multi-modal Factorization Model, MFM) combina múltiples conjuntos de datos a través de la factorización matricial para crear un espacio de representación común. El Embebido Binario Discriminativo Multimodal (Multi-modal Discriminative Binary Embedding, MDBE) es un método que representa los datos multimodales como códigos binarios.
En investigaciones recientes, se han propuesto métodos como COSA (Concatenated Sample), que conecta secuencialmente múltiples pares imagen-texto y aplica modelos basados en transformers para aprender conjuntamente el contenido visual y las pistas temporales. Además, la Concatenación Atencional es un método para generar imágenes de alta resolución a partir del texto, utilizando una estructura en cascada de múltiples niveles y empleando los resultados de capas anteriores junto con vectores de palabras como entrada para capas posteriores.
Ejemplo de estructura
A continuación se muestra la ilustración de tres métodos de fusión (Concatenation, MFM, MDBF).
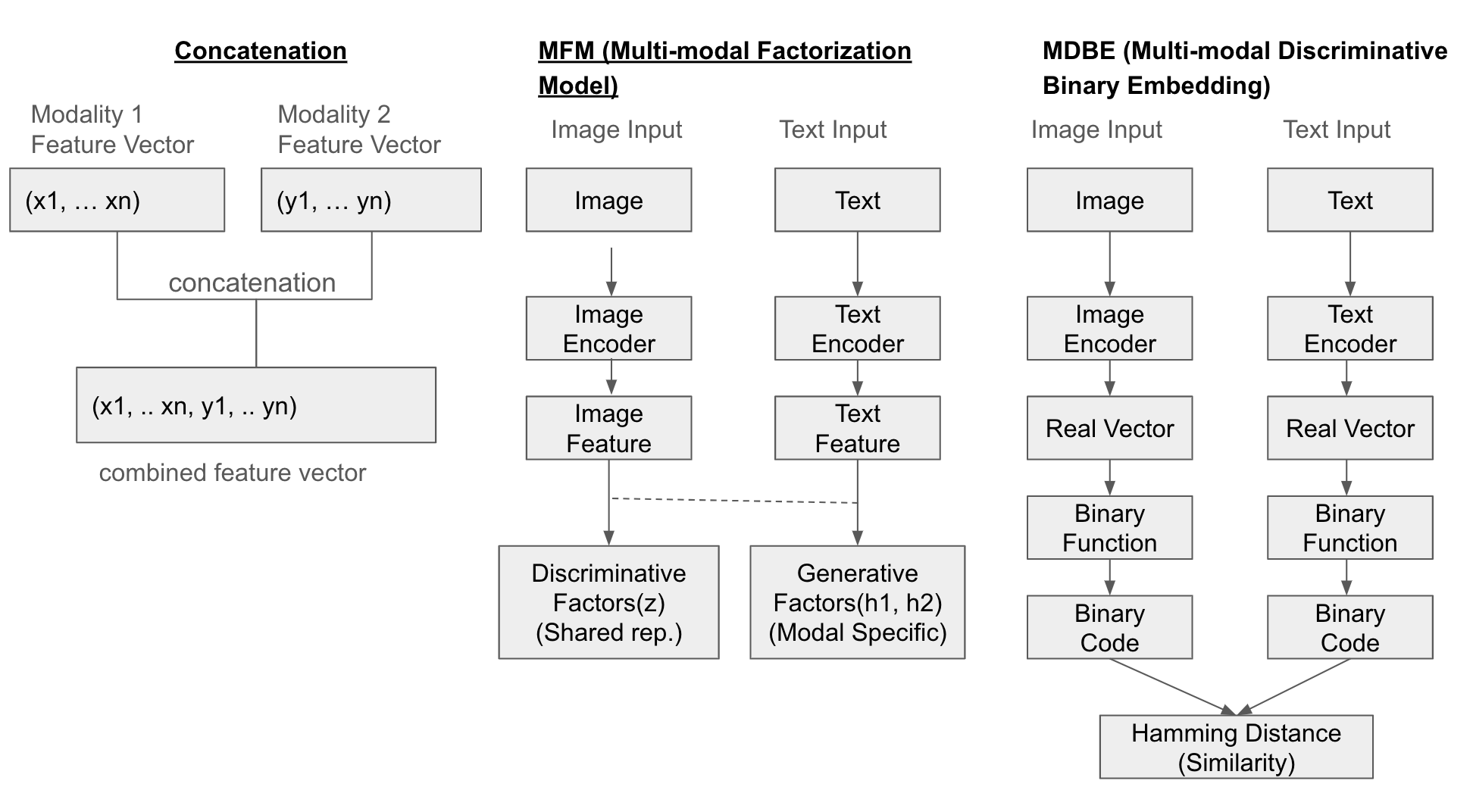
Ejemplo
from transformers import AutoModel, AutoProcessor, AutoTokenizer
from PIL import Image
import torch
import requests
import matplotlib.pyplot as plt
# Load pre-trained models and processor/tokenizer for image and text
image_model_name = "google/vit-base-patch16-224-in21k" # ViT (Vision Transformer)
text_model_name = "bert-base-uncased" # BERT
image_processor = AutoProcessor.from_pretrained(image_model_name)
image_model = AutoModel.from_pretrained(image_model_name)
tokenizer = AutoTokenizer.from_pretrained(text_model_name)
text_model = AutoModel.from_pretrained(text_model_name)
# Example image and text
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "Two cats sleeping on a couch."
# Display the image
plt.imshow(image)
plt.axis('off') # Remove axes
plt.show()
# Preprocess image and text
image_inputs = image_processor(images=image, return_tensors="pt")
text_inputs = tokenizer(text, return_tensors="pt")
# Feature extraction (embeddings) for each modality
with torch.no_grad(): # Disable gradient calculation (inference mode)
image_features = image_model(**image_inputs).last_hidden_state[:, 0, :] # [CLS] token embedding
text_features = text_model(**text_inputs).last_hidden_state[:, 0, :] # [CLS] token embedding
# Create Joint Representation (Concatenation)
joint_representation = torch.cat((image_features, text_features), dim=1)
print("Image Features Shape:", image_features.shape) # Image feature vector size
print("Text Features Shape:", text_features.shape) # Text feature vector size
print("Joint Representation Shape:", joint_representation.shape) # Combined feature vector size (image + text)Fast image processor class <class 'transformers.models.vit.image_processing_vit_fast.ViTImageProcessorFast'> is available for this model. Using slow image processor class. To use the fast image processor class set `use_fast=True`.
Image Features Shape: torch.Size([1, 768])
Text Features Shape: torch.Size([1, 768])
Joint Representation Shape: torch.Size([1, 1536])Las Representaciones Coordinadas son un enfoque que representa cada modalidad en espacios separados, pero aprende explícitamente las relaciones entre ellos. Es similar a tener varios dibujos en diferentes lienzos, asegurando que cada lienzo se armonice con los demás.
Cada modalidad se representa mediante vectores de características distintos, pero estos vectores son entrenados para “coordinarse” entre sí. Esto significa que, aunque los espacios de características de cada modalidad sean independientes, aprenden las similitudes, relaciones de orden, etc., para establecer relaciones significativas entre ellos. La ventaja de este enfoque es que puede preservar al máximo las características únicas de cada modalidad, mientras considera la relevancia con otras modalidades. Además, permite aprender diversas formas de relaciones entre modalidades, lo que lo hace aplicable a una amplia gama de problemas multimodales.
Sin embargo, dado que cada modalidad se procesa por separado, la estructura del modelo puede ser más compleja en comparación con las Representaciones Conjuntas. Esto puede dificultar el diseño y entrenamiento del modelo. Además, aprender explícitamente las relaciones entre modalidades es un desafío.
Un ejemplo destacado es CLIP (Contrastive Language-Image Pre-training). CLIP procesa imágenes y texto mediante codificadores separados para obtener vectores de características y luego aprende la similitud entre ellos. CLIP se entrena para que las imágenes y el texto sean “parejas” entre sí, estableciendo relaciones significativas entre imagen y texto.
El éxito de CLIP es particularmente notable en su capacidad de aprendizaje zero-shot. El modelo pre-entrenado de CLIP puede clasificar o buscar nuevas imágenes sin necesidad de entrenamiento adicional para una tarea específica. Esto es posible debido a la efectiva aprendizaje de conexiones semánticas entre texto e imagen.
Ejemplo de estructura
A continuación se muestra una ilustración de la fusión en CLIP.
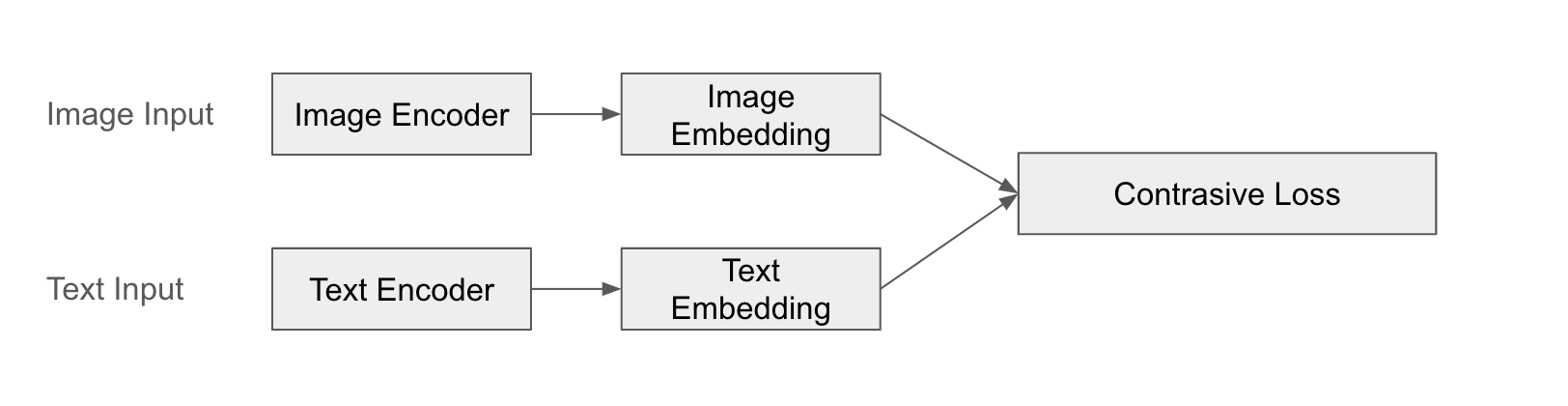
Ejemplo
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import torch
import requests
import matplotlib.pyplot as plt
# Load CLIP model and processor
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Example image and text
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "Two cats sleeping on a couch."
# Display image
plt.imshow(image)
plt.axis('off') # Remove axes
plt.show()
# Preprocess image and text
inputs = processor(text=[text], images=image, return_tensors="pt", padding=True)
# Extract image and text features (embeddings)
with torch.no_grad():
outputs = model(**inputs)
image_features = outputs.image_embeds
text_features = outputs.text_embeds
# Coordinated Representation: Keep features of each modality separate
print("Image Features Shape:", image_features.shape)
print("Text Features Shape:", text_features.shape)
# Calculate similarity between image and text (dot product)
similarity = torch.matmul(image_features, text_features.T) # Or text_features @ image_features.T
print("Image-Text Similarity:", similarity.item())
Image Features Shape: torch.Size([1, 512])
Text Features Shape: torch.Size([1, 512])
Image-Text Similarity: 0.29803216457366943Aplicando el método anterior, es posible realizar una prueba de zero-shot de la siguiente manera.
# Zero-shot 이미지 분류
# - 여러 텍스트 후보군을 만들고, 각 텍스트와 이미지 간의 유사도를 계산하여 가장 높은 유사도를 갖는 텍스트를 선택
candidate_texts = ["a photo of a cat", "a photo of a dog", "a photo of a bird"]
inputs = processor(text=candidate_texts, images=image, return_tensors="pt", padding=True)
with torch.no_grad():
outputs = model(**inputs)
image_features = outputs.image_embeds
text_features = outputs.text_embeds
logits_per_image = outputs.logits_per_image # 유사도 점수
probs = logits_per_image.softmax(dim=1) # 확률
predicted_class_idx = probs.argmax().item()
predicted_class = candidate_texts[predicted_class_idx]
print("Predicted Class:", predicted_class)
print("Probabilities:", probs)Predicted Class: a photo of a cat
Probabilities: tensor([[9.9403e-01, 5.1377e-03, 8.3070e-04]])El codificador-decodificador es un método que convierte datos de una modalidad en datos de otra modalidad. Es una técnica comúnmente utilizada en la traducción de lenguajes.
En esta estructura, el codificador (Encoder) convierte los datos de la modalidad de entrada (por ejemplo, imágenes) en vectores de características. Este vector de características representa de manera concisa la información clave de los datos de entrada. El decodificador (Decoder) genera datos de otra modalidad (por ejemplo, texto) basándose en el vector de características creado por el codificador. El decodificador “interpreta” la salida del codificador para generar un nuevo tipo de datos. Además, mediante el mecanismo de atención, el decodificador aprende a qué partes del vector de características del codificador debe “prestar atención” al generar los datos de salida.
Una ventaja de este enfoque es que se puede aplicar a diversas tareas que conectan formas diferentes de datos, como la generación de descripciones para imágenes, P+R visual (Pregunta-Respuesta Visual), y traducción automática. Además, es aplicable incluso cuando las modalidades de entrada y salida son diferentes, permitiendo combinaciones variadas como texto-imagen, imagen-texto, audio-texto, etc.
Un ejemplo destacado es la generación de descripciones para imágenes y P+R visual (Pregunta-Respuesta Visual). En la generación de descripciones para imágenes, se procesa la imagen con el codificador para obtener un vector de características, y luego se utiliza el decodificador para generar una descripción (texto). En P+R visual, se procesan tanto la imagen como la pregunta (texto) con sus respectivos codificadores, y se utiliza un mecanismo de atención para determinar la relevancia entre la imagen y la pregunta antes de usar el decodificador para generar una respuesta (texto).
Sin embargo, si los datos de entrada o salida son largos, puede ocurrir pérdida de información o aumento en la cantidad de cálculos. En particular, en modelos basados en RNN, el problema de desaparición del gradiente (gradient vanishing problem) puede dificultar el aprendizaje de dependencias a largo plazo. Además, al tener que aprender tanto el codificador como el decodificador simultáneamente, el proceso de entrenamiento puede ser inestable o difícil.
Ejemplo de estructura
Lo siguiente es una representación diagramática de la fusión de codificador-decodificador.
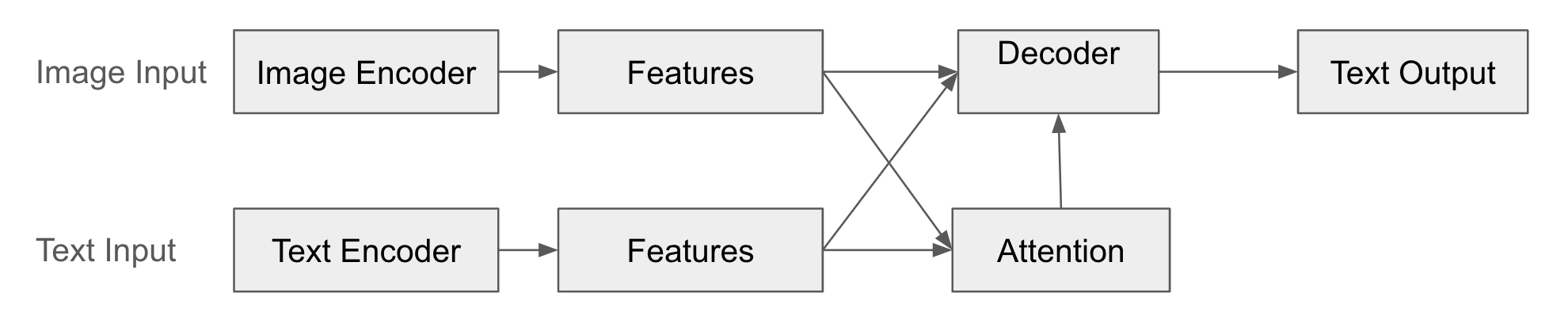
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
import requests
import matplotlib.pyplot as plt
# Load model and processor
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# Download image
url = "http://images.cocodataset.org/val2017/000000000139.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# Display image
plt.imshow(image)
plt.axis('off')
plt.show()
# Input text (optional - Conditional Generation)
# text = "describe this image:" # Prompt (guide image description)
text = "a photo of"
# Preprocess image and text (optional)
# If text is provided, it uses the text as a prompt to generate the caption.
inputs = processor(image, text=text, return_tensors="pt")
# Generate caption
outputs = model.generate(**inputs)
# Decode and print caption
caption = processor.decode(outputs[0], skip_special_tokens=True)
print("Generated caption:", caption)
Generated caption: a photo of a living room with a television and a fireplaceEste ejemplo muestra la imagen captioning, que es un caso típico de la estructura Encoder-Decoder. El codificador recibe una imagen (el codificador visual de BLIP) y extrae un vector de características. El decodificador genera texto (el decodificador de texto de BLIP). A través del mecanismo de atención, se decide a qué partes del vector de características de la imagen prestar atención mientras se genera el caption. Se pueden especificar prompts que influyen en el caption generado como texto. Aunque BLIP puede utilizar tanto imágenes como texto como entrada, aquí solo se usa una imagen como entrada y el texto se genera en el decodificador.
En las secciones 10.3.1, 10.3.2, 10.3.3 se han examinado las tres teorías clave de la fusión multimodal: Joint Representations, Coordinated Representations, Encoder-Decoder. Cada enfoque tiene sus propias características y ventajas y desventajas, por lo que es importante seleccionar el método adecuado según el campo de aplicación.
La “fusión” en el aprendizaje profundo multimodal es un proceso clave que combina información de diferentes modalidades para crear representaciones más ricas y poderosas. Aunque en la sección 10.3 revisamos brevemente la teoría de fusión basada en las lecciones de CMU, la investigación real sobre fusión multimodal ha evolucionado de manera mucho más diversa y dinámica. En este análisis detallado, examinaremos varios sistemas de clasificación de la fusión y tendencias de investigación recientes, así como las tecnologías que están ganando atención en 2025.
La fusión multimodal es difícil de clasificar con un solo criterio. Los investigadores han categorizado los métodos de fusión desde diferentes perspectivas, y cada clasificación no es mutuamente excluyente sino complementaria.
Esta clasificación se centra en la “etapa” del modelo de aprendizaje profundo multimodal donde ocurre la fusión. (Ver sección 10.3.4 del texto)
Early Fusion (Fusión Temprana): Combina los datos “crudos” (o características procesadas muy temprano) de cada modalidad en la etapa de entrada del modelo.
Late Fusion (Fusión Tardía): Procesa cada modalidad con modelos separados y combina las salidas de los modelos (por ejemplo, resultados de predicción) en la última etapa.
Hybrid Fusion (Fusión Híbrida): Combina los métodos de fusión temprana y tardía. Realiza la fusión en múltiples etapas del modelo para aprovechar información a diferentes niveles.
Fusión Model-Agnostic: Técnicas de fusión generales que no dependen de un modelo específico (Early, Late, Hybrid Fusion, etc.).
Fusión Model-Specific: Técnicas de fusión especializadas para estructuras de modelos específicas.
Investigación más reciente: En el taller CVPR (MULA 2025) programado para los días 11-12 de junio de 2025, se discutirán investigaciones sobre estructuras de modelos para fusionar eficazmente diversos datos sensoriales (cámara, LiDAR, radar, etc.) en el campo de la conducción autónoma. Este taller tiene como objetivo fomentar la interacción y colaboración interdisciplinaria entre las comunidades de visión por computadora, multimedia, teledetección y robótica, con un enfoque particular en los enfoques multimodales para la conducción autónoma.
Fusión simétrica vs. asimétrica:
Simétrica: Trata todos los modos de manera igual.
Asimétrica: Da más peso a ciertos modos o les asigna diferentes roles.
Investigación reciente: “Learning Deep Multimodal Feature Representation with Asymmetric Multi-layer Fusion” propuso un marco efectivo para fusionar características multimodales en múltiples capas dentro de una sola red. Esta investigación introduce dos operaciones de fusión asimétrica, shuffle de canales y shift de píxeles, que aprenden diferentes características según las direcciones de fusión. Además, “Multimodal sentiment analysis based on multi-layer feature fusion” presentado en enero de 2025 propuso un nuevo enfoque para el análisis preciso del sentimiento en condiciones de desequilibrio modal e implicaciones implícitas.
Fusión explícita vs. implícita:
Explícita: Define o modela explícitamente las relaciones entre los modos. (Ejemplo: mecanismos de atención)
Implícita: No define directamente las relaciones entre los modos, sino que permite que el modelo aprenda estas relaciones por sí mismo. (Ejemplo: combinación simple)
Investigación reciente: Se espera que en la Conferencia HCI International 2025 (junio de 2025) se presente una investigación comparando las ventajas y desventajas de la fusión explícita y la fusión implícita.
El mecanismo de fusión basada en atención es el enfoque más destacado en las investigaciones de 2024-2025.
Concepto: Se utiliza una característica de un modo como consulta (query) para aplicar la atención a otra característica (key-value) del otro modo. (Ver sección 10.4.2) De esta manera, el modelo puede comprender con precisión qué elementos específicos de un modo están relacionados con los elementos de otro.
Investigación reciente
En enero de 2025, “Bi-Att3DDet” presentó un método de fusión basada en atención bidireccional para la detección de objetos 3D en conducción autónoma. Esta investigación propone una interacción bidireccional para maximizar la información complementaria entre los datos de LiDAR y cámara.
“LANMSFF” presentado en marzo de 2024 y revisado en febrero de 2025, combinó una red neuronal basada en atención ligera con fusión de características multiscale para el reconocimiento de expresiones faciales multi-vista. Este enfoque genera mapas de atención canal y espacial simultáneamente para destacar características importantes e inhibir las irrelevantes.
Recientes investigaciones neurocientíficas (2025) han examinado el impacto de la congruencia cruzada modal (cross-modal congruency) en el procesamiento y acumulación de información sensorial. Estos estudios demostraron que la congruencia entre estímulos auditivos y visuales desempeña un papel crucial en las etapas iniciales del procesamiento sensorial. #### 2.2 Atención Multi-cabeza
Concepto: Se utilizan múltiples cabezas de atención para capturar las relaciones entre modalidades desde diferentes perspectivas. Cada cabeza utiliza matrices de pesos diferentes (W_Q, W_K, W_V) para transformar los datos de entrada y calcular la atención, por lo que cada cabeza puede concentrarse en diferentes aspectos de los datos de entrada (por ejemplo, significado, estructura gramatical, estilo).
Ventajas: Puede modelar diferentes tipos de relaciones simultáneamente, lo que permite aprender representaciones más ricas y complejas. Por ejemplo, al fusionar imágenes y texto, algunas cabezas pueden concentrarse en las relaciones entre los objetos en la imagen y las palabras en el texto, mientras que otras cabezas pueden centrarse en las relaciones entre la atmósfera general de la imagen y el tono del texto.
Investigación reciente: Los modelos multimodales a gran escala (LMM) han ampliado y refinado esta técnica para modelar eficazmente interacciones complejas entre diferentes modalidades, como imágenes, texto, audio y video.
Aprendizaje contrastivo (Contrastive Learning):
Concepto: Se aprende a posicionar pares de modalidades relacionadas (por ejemplo, una imagen y su leyenda correspondiente) cerca en el espacio de embeddings, mientras que los pares no relacionados se posicionan lejos.
Ventajas: Permite aprender eficazmente incluso con grandes conjuntos de datos sin etiquetas, lo que ayuda a resolver problemas de escasez de datos.
Investigación reciente: “Dual-Level Cross-Modal Contrastive Clustering” (2024) propone un nuevo método de aprendizaje contrastivo para cerrar la brecha entre las representaciones visuales y los significados del texto.
Aprendizaje basado en máscaras (Masking-based Learning):
Concepto: Se aprende a reconstruir una parte de la entrada que ha sido enmascarada utilizando información de otra modalidad.
Ventajas: Permite aprender relaciones complementarias entre modalidades. Por ejemplo, se puede aprender a predecir partes ocultas de una imagen usando descripciones de texto o a predecir palabras ocultas en un texto usando una imagen.
Investigación reciente: CAST (2025) mejoró el alineamiento entre nodos de estructuras gráficas y tokens de texto mediante la estrategia de preentrenamiento Masked Node Prediction (MNP).
Fusión a nivel de token (Token-level Fusion): Modela las interacciones detalladas entre tokens individuales de cada modalidad (por ejemplo, parches de imagen, tokens de texto).
Ventajas: Permite capturar relaciones más precisas entre modalidades. Por ejemplo, puede aprender la relación directa entre un objeto específico en una imagen y una palabra específica en el texto.
Investigación reciente: CAST (2025) demostró que la fusión a nivel de token entre nodos gráficos y tokens de texto en ciencias de materiales es superior a la fusión a nivel de instancia.
Fusión a nivel de instancia (Instance-level Fusion): Trata las instancias completas de cada modalidad (por ejemplo, una imagen completa, un texto completo) como una única unidad para su fusión.
Ventajas: Es computacionalmente eficiente y fácil de implementar.
Desventajas: Puede no capturar relaciones detalladas dentro de las modalidades.
La fusión multimodal puede clasificarse de diversas formas, y cada forma de clasificación ofrece una perspectiva diferente. En la investigación práctica, es común combinar estas clasificaciones para aprovechar sus fortalezas. En 2025, la investigación de fusión multimodal se centra en el desarrollo de técnicas eficientes de fusión utilizando interacciones detalladas a nivel de token, mecanismos de atención cruzada y métodos de aprendizaje autónomo. En particular, eventos académicos importantes como el taller CVPR 2025 (junio del 25, Nashville) discutirán activamente el progreso de las tecnologías de fusión multimodal en diversos campos de aplicación, como conducción autónoma, diagnóstico médico y ciencia de materiales.
A través de este profundización, se espera comprender diversas clasificaciones de la fusión multimodal y analizar más a fondo los distintos modelos multimodales que se presentarán.
Ingrese el texto en coreano aquí.
De las secciones 10.3.1 a 10.3.3, hemos examinado los métodos para fusionar datos multimodales. Esta es una clasificación teórica. Al diseñar un modelo multimodal real, es necesario decidir estratégicamente qué método de fusión, en qué punto y cómo aplicarlo según las características del problema y los datos dados. En esta sección, examinaremos las estrategias sofisticadas de integración modal adoptadas por los modelos multimodales más recientes.
La fusión temprana combina las entradas de múltiples modalidades en una etapa inicial del modelo. La forma más simple es concatenar los vectores de características de cada modalidad. La ventaja de la fusión temprana es que facilita capturar interacciones de bajo nivel (low-level) entre modalidades. Por ejemplo, si el color de una imagen y ciertas palabras en un texto están fuertemente relacionadas, la fusión temprana puede facilitar el aprendizaje de estas relaciones. Sin embargo, tiene la desventaja de que puede no aprovechar adecuadamente las características de cada modalidad. Especialmente cuando se requiere procesamiento especializado para cada modalidad (por ejemplo, CNN para imágenes, RNN para texto), la fusión temprana puede ser ineficiente.
Las investigaciones recientes también han presentado benchmarks que evalúan el rendimiento de la fusión temprana en entornos de datos multimodales ruidosos (noisy data) y con alta incertidumbre, además del simple concatenamiento.
Veamos un ejemplo sencillo de fusión temprana. Aquí usamos concatenación para realizar una representación conjunta. Se utiliza el mismo código. Al final, se aplica un clasificador lineal simple para determinar si hay un gato o no.
from transformers import AutoModel, AutoProcessor, AutoTokenizer
from PIL import Image
import torch
import requests
import matplotlib.pyplot as plt
# 이미지와 텍스트를 위한 사전 학습된 모델 및 프로세서/토크나이저 로드
image_model_name = "google/vit-base-patch16-224-in21k" # ViT (Vision Transformer)
text_model_name = "bert-base-uncased" # BERT
image_processor = AutoProcessor.from_pretrained(image_model_name)
image_model = AutoModel.from_pretrained(image_model_name)
tokenizer = AutoTokenizer.from_pretrained(text_model_name)
text_model = AutoModel.from_pretrained(text_model_name)
# 예제 이미지 및 텍스트
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "Two cats sleeping on a couch."
# 이미지 출력
plt.imshow(image)
plt.axis('off') # 축 제거
plt.show()
# 이미지와 텍스트 전처리
image_inputs = image_processor(images=image, return_tensors="pt")
text_inputs = tokenizer(text, return_tensors="pt")
# 각 모달리티에 대한 특징 추출 (임베딩)
with torch.no_grad(): # 기울기 계산 비활성화 (추론 모드)
image_features = image_model(**image_inputs).last_hidden_state[:, 0, :] # [CLS] 토큰 임베딩
text_features = text_model(**text_inputs).last_hidden_state[:, 0, :] # [CLS] 토큰 임베딩
# Joint Representation 생성 (Concatenation)
joint_representation = torch.cat((image_features, text_features), dim=1)
print("Image Features Shape:", image_features.shape) # 이미지 특징 벡터 크기
print("Text Features Shape:", text_features.shape) # 텍스트 특징 벡터 크기
print("Joint Representation Shape:", joint_representation.shape) # 결합된 특징 벡터 크기 (image + text)
# Joint Representation을 활용한 추가 작업 (예: 분류)
num_labels = 2 # 예: "고양이 없음(0)" "고양이 있음(1)", 두 가지 클래스로 분류
classifier = torch.nn.Linear(joint_representation.size(1), num_labels) # 간단한 선형 분류기
outputs = classifier(joint_representation)
print("Classification Outputs:", outputs)Fast image processor class <class 'transformers.models.vit.image_processing_vit_fast.ViTImageProcessorFast'> is available for this model. Using slow image processor class. To use the fast image processor class set `use_fast=True`.
Image Features Shape: torch.Size([1, 768])
Text Features Shape: torch.Size([1, 768])
Joint Representation Shape: torch.Size([1, 1536])
Classification Outputs: tensor([[0.1817, 0.0355]], grad_fn=<AddmmBackward0>)En el ejemplo anterior, las imágenes y el texto se combinan directamente con la salida de modelos separados denominados ViT y BERT, respectivamente. No se realiza un procesamiento adicional (atención, transformaciones complejas, etc.) en estos dos vectores antes de combinar las características de imagen y texto. Por lo tanto, esto corresponde a una fusión temprana.
La fusión tardía implica procesar cada modalidad con modelos separados y combinar la salida de cada modelo (por ejemplo, los resultados de predicción) en la última etapa. La ventaja de este método es que se pueden usar modelos especializados para cada modalidad. Por ejemplo, se puede utilizar una CNN pre-entrenada para imágenes y un Transformer pre-entrenado para texto, lo que permite extraer eficazmente características complejas de cada modalidad. Sin embargo, esta técnica solo considera interacciones de alto nivel entre las modalidades, lo que dificulta el intercambio de información en etapas intermedias.
La fusión tardía se ha estudiado activamente para combinar la salida de modelos de diferentes modalidades y mejorar el rendimiento, similar a las técnicas de ensemble.
La fusión híbrida es una combinación de Early Fusion y Late Fusion. Se realiza la fusión en múltiples etapas del modelo para aprovechar información a diferentes niveles. La ventaja de este método es que puede incorporar las ventajas tanto de Early Fusion como de Late Fusion, es decir, considerar interacciones de bajo nivel y alto nivel entre modalidades. Sin embargo, esto también conlleva una mayor complejidad en la estructura del modelo y un aumento en el número de hiperparámetros a ajustar.
Un ejemplo representativo de fusión híbrida es la Cross-Modal Attention, que implica aplicar atención a las características de una modalidad (key-value) utilizando las características de otra modalidad como consulta (query). Este método es típico para realizar la fusión en etapas intermedias.
En investigaciones recientes, además de la atención, se han explorado otras técnicas como mecanismos con puertas y pooling bilineal para realizar fusiones en etapas intermedias.
Desde 2023, modelos multimodales a gran escala (LMM) como Gemini y GPT-4V han implementado estrategias de integración de modalidades más sofisticadas para mejorar significativamente el rendimiento.
El mecanismo de fusión selectiva (Selective Fusion Mechanism) evalúa dinámicamente la importancia de cada modalidad y combina la información de manera selectiva. Por ejemplo, si una imagen contiene texto, se fortalece la asociación entre las características visuales del área de texto y el contenido del texto. Esto es similar a cómo las personas ajustan la importancia de la información visual y textual según las necesidades específicas.
El ajuste automático de contribución (Task-Specific Fusion) optimiza la forma de integrar modalidades según los requisitos de tareas específicas. En el caso del captioning de imágenes, se enfatiza en la transformación unidireccional de información visual a texto, mientras que en las respuestas visuales a preguntas, se refuerza la interacción bidireccional.
Estas estrategias sofisticadas de integración han mejorado significativamente el rendimiento de los modelos multimodales. En particular, al ir más allá de la simple combinación de información y ajustar dinámicamente el rol e importancia de cada modalidad, así como optimizar la fusión según las características de la tarea, estos modelos han demostrado excelentes resultados en tareas que requieren inferencias complejas. Estas estrategias de integración requieren conjuntos de datos a gran escala y recursos computacionales, por lo que es difícil implementarlas y experimentar con ellas directamente a través de ejemplos de aprendizaje. En su lugar, es recomendable obtener una comprensión conceptual a través de los artículos y documentos técnicos de cada modelo.
En la sección 10.3, examinamos diversas metodologías y estrategias teóricas para fusionar datos multimodales. A partir de esto, revisaremos técnicas específicas sobre cómo los modelos multimodales reales representan eficazmente la información de cada modalidad y aprenden las relaciones entre diferentes modalidades. La implementación completa se encuentra en chapter_10/multimodal_embeding.py.
Una de las tareas centrales del aprendizaje multimodal es cómo representar modalidades con características diferentes en un espacio común significativo. Las imágenes son arreglos bidimensionales de valores de píxeles, el texto es una secuencia unidimensional de tokens, y el audio es valores de amplitud a lo largo del tiempo; cada modalidad tiene su propia forma de representación única. Para procesar eficazmente estos datos heterogéneos, se necesita una técnica de aprendizaje de representaciones que mantenga las características intrínsecas de cada modalidad y capture sus relaciones semánticas.
Enfoque inicial: codificadores individuales + proyección
Los modelos multimodales iniciales utilizaban codificadores especializados para cada modalidad (por ejemplo, CNN para imágenes, RNN para texto) para extraer vectores de características, y luego los proyectaban a un espacio vectorial común mediante una transformación lineal o una MLP (Multi-Layer Perceptron) somera. (Consulte el método de Representación Conjunta, Concatenación en la sección 10.3.1)
Enfoque reciente: alineación semántica
Recientemente, se ha dado prioridad a un enfoque que va más allá del simple ajuste dimensional y busca que los vectores de características de cada modalidad estén “alineados” semanticamente entre sí. Es decir, las imágenes relacionadas y el texto deben estar cerca en el espacio de incrustación, mientras que las imágenes no relacionadas y el texto deben estar lejos.
Aprendizaje contrastivo: (Consulte la Representación Coordinada en la sección 10.3.2, ejemplo de CLIP) Se considera un par imagen-texto como una muestra “positiva” y un par imagen-texto mezclado aleatoriamente como una muestra “negativa”, y se aprende aumentando la similitud entre las muestras positivas y disminuyendo la similitud entre las muestras negativas.
Pérdida de tripletas: Se usan tres elementos: una imagen ancla, un texto positivo (el caption correspondiente a la imagen) y un texto negativo (el caption de otra imagen), para aprender que la distancia entre la imagen ancla y el texto positivo sea cercana, mientras que la distancia entre la imagen ancla y el texto negativo sea lejana.
Ejemplo de implementación (Aprendizaje contrastivo)
class MultimodalEmbedding(nn.Module):
def __init__(self, embedding_dim=512):
super().__init__()
self.image_encoder = models.resnet18(pretrained=True)
self.image_encoder.fc = nn.Sequential(
nn.Linear(512, embedding_dim),
nn.LayerNorm(embedding_dim)
)
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.text_projection = nn.Sequential(
nn.Linear(768, embedding_dim), # BERT output dimension is 768
nn.LayerNorm(embedding_dim)
)
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
def encode_image(self, image):
return self.image_encoder(image)
def encode_text(self, input_ids, attention_mask):
text_features = self.text_encoder(input_ids, attention_mask)[0][:, 0, :] # [CLS] token, keep batch dim
return self.text_projection(text_features)MultimodalEmbedding clase:
image_encoder: Utiliza ResNet18 para convertir imágenes en vectores de características de tamaño embedding_dim.text_encoder: Utiliza el modelo BERT para convertir texto en vectores de características y ajustarlos a un tamaño embedding_dim mediante la capa text_projection.logit_scale: Es un parámetro de temperatura aprendible utilizado en CLIP.Mecanismo de alineación semántica
La alineación semántica se implementa principalmente en las siguientes dos partes: el método forward de la clase MultimodalEmbedding y constrasive_loss().
def forward(self, image, input_ids, attention_mask):
image_features = self.encode_image(image)
text_features = self.encode_text(input_ids, attention_mask)
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
logit_scale = self.logit_scale.exp()
logits = logit_scale * image_features @ text_features.transpose(-1, -2)
# print("logits:", logits.shape)
return logits # Return a single valueforward método:
Usa encode_image y encode_text para codificar las imágenes y el texto, respectivamente.
Normalización de características (Feature Normalization): Ajusta la magnitud de los vectores image_features y text_features a 1 mediante normalización L2 (L2 normalization). Esto se hace para considerar solo la dirección del vector al calcular la similitud.
Escalado de temperatura (Temperature Scaling): Ajusta la distribución de las puntuaciones de similitud utilizando logit_scale. Se aplica el valor logit_scale a una función exponencial para obtener un factor de escala, que luego se multiplica por el producto matricial del tensor de características de imagen y el tensor de características de texto transpuesto. El producto matricial calcula los productos internos (dot products) entre cada vector de características de imagen y todos los vectores de características de texto para generar las puntuaciones de similitud.
logits: Calcula la similitud (productos internos) entre los vectores de características de imagen y los vectores de características de texto. Se utiliza text_features.transpose(-1, -2) en lugar de text_features.t() para realizar la transposición. Esto intercambia las dos últimas dimensiones del tensor de características de texto, cambiando su forma de (lote, dimensión de características de texto) a (lote, dimensión de características, texto), lo que permite multiplicarlo con el tensor de características de imagen de forma (lote, dimensión de características de imagen).
def contrastive_loss(logits): # removed enhanced_similarity
labels = torch.arange(logits.size(0), device=logits.device) # Use logits.size(0)
# Image-to-text and text-to-image contrastive loss
img_txt_loss = nn.CrossEntropyLoss()(logits, labels)
txt_img_loss = nn.CrossEntropyLoss()(logits.T, labels)
# Average loss
return (img_txt_loss + txt_img_loss) / 2La función contrastive_loss genera labels como enteros desde 0 hasta (tamaño del lote - 1) para ajustarse al tamaño de la matriz logits. Los elementos diagonales (i, i) en la matriz logits representan la similitud entre la i-ésima imagen y el i-ésimo texto. Es decir, estas entradas diagonales representan la similitud del par positivo (imagen y texto correspondientes), por lo que se configuran las etiquetas para que estos elementos diagonales sean los correctos. Además, img_txt_loss calcula la pérdida de similitud de imagen a texto (image-to-text loss), mientras que txt_img_loss calcula la pérdida de similitud de texto a imagen (text-to-image loss). Al promediar estas dos pérdidas, se tiene en cuenta el alineamiento semántico bidireccional (de imagen a texto y de texto a imagen).
El mecanismo de alineamiento semántico mapea las características de diferentes modalidades a un espacio semánticamente coherente. Primero, se proyectan todos los vectores de características a una esfera unitaria mediante la normalización L2 para eliminar las diferencias de escala entre las modalidades. Se introduce un parámetro de escalado de temperatura para ajustar la distribución de valores de similitud. Una alta temperatura produce una distribución más suave, mientras que una baja temperatura genera una distribución más aguda, lo cual mejora la estabilidad del aprendizaje. Además, a través del aprendizaje contrastivo, se entrena para que las parejas imagen-texto relacionadas estén cercanas y las no relacionadas estén lejanas en el espacio de incrustación. En particular, se optimiza simultáneamente el mapeo de imagen a texto y de texto a imagen para lograr un alineamiento semántico bidireccional.
Al igual que en el aprendizaje contrastivo de CLIP, los contenidos relacionados se aprenden a estar cercanos y los no relacionados lejanos. Esta estrategia de alineamiento semántico basada en aprendizaje contrastivo ha evolucionado desde la introducción del CLIP por OpenAI en 2021 hasta el PaLM-E de Google, el Claude de Anthropic y el Gemini de DeepMind. Mientras que el CLIP inicial se centraba principalmente en el aprendizaje contrastivo simple de pares imagen-texto, los modelos más recientes capturan relaciones intermodales con mayor sofisticación. En particular, Gemini aprende simultáneamente el alineamiento semántico entre diferentes modalidades como imágenes, texto, audio y video, construyendo un espacio de significado integrado que preserva las características únicas de cada modalidad.
Ejemplo de ejecución
Se utiliza el conjunto de datos flicker8k para el entrenamiento. Se puede utilizar la función train_multimodal_embedding para entrenar el modelo EnhancedMultimodalEmbedding (o EnhancedMultimodalEmbedding_no_p) con el conjunto de datos Flickr8k. En la función main, se configuran el modelo, el cargador de datos, el optimizador, etc., y al llamar a la función train_multimodal_embedding, comienza el entrenamiento.
# download flickr8k.
!mkdir data;cd data;wget "https://github.com/awsaf49/flickr-dataset/releases/download/v1.0/flickr8k.zip";unzip -q flickr8k.zip -d ./flickr8kmkdir: cannot create directory ‘data’: File exists
--2025-03-09 16:33:12-- https://github.com/awsaf49/flickr-dataset/releases/download/v1.0/flickr8k.zip
Resolving github.com (github.com)... 20.200.245.247
Connecting to github.com (github.com)|20.200.245.247|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://objects.githubusercontent.com/github-production-release-asset-2e65be/753516996/d7c62b13-1e50-40ea-8fae-f34a44b1695f?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=releaseassetproduction%2F20250309%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20250309T073156Z&X-Amz-Expires=300&X-Amz-Signature=ff62cf7df8ac3deba8bd6f4f775e164abf03c6d2d6d86d740e5407e52702c6a3&X-Amz-SignedHeaders=host&response-content-disposition=attachment%3B%20filename%3Dflickr8k.zip&response-content-type=application%2Foctet-stream [following]
--2025-03-09 16:33:12-- https://objects.githubusercontent.com/github-production-release-asset-2e65be/753516996/d7c62b13-1e50-40ea-8fae-f34a44b1695f?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=releaseassetproduction%2F20250309%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20250309T073156Z&X-Amz-Expires=300&X-Amz-Signature=ff62cf7df8ac3deba8bd6f4f775e164abf03c6d2d6d86d740e5407e52702c6a3&X-Amz-SignedHeaders=host&response-content-disposition=attachment%3B%20filename%3Dflickr8k.zip&response-content-type=application%2Foctet-stream
Resolving objects.githubusercontent.com (objects.githubusercontent.com)... 185.199.109.133, 185.199.111.133, 185.199.110.133, ...
Connecting to objects.githubusercontent.com (objects.githubusercontent.com)|185.199.109.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1112971163 (1.0G) [application/octet-stream]
Saving to: ‘flickr8k.zip’
flickr8k.zip 100%[===================>] 1.04G 56.8MB/s in 19s
2025-03-09 16:33:32 (56.9 MB/s) - ‘flickr8k.zip’ saved [1112971163/1112971163]
import torch
from torchvision import models, transforms
from torch.utils.data import Dataset, DataLoader
# Assuming dldna.chapter_10.multimodal_embedding is in the same directory or Python path.
# Adjust if necessary (e.g., from multimodal_embedding import ...).
from dldna.chapter_10.multimodal_embedding import Flickr8kDataset, MultimodalEmbedding, train_multimodal_embedding, generate_example
# Data transformation setup
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# Dataset and DataLoader setup
image_dir = './data/flickr8k/Images' # Replace with the actual path to your image directory
caption_file = './data/flickr8k/captions.txt' # Replace with the actual path to your caption file
dataset = Flickr8kDataset(image_dir, caption_file, transform=transform)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4)
# Model initialization
model = MultimodalEmbedding()
# Model training
train_multimodal_embedding(model, train_loader, val_loader, num_epochs=3)
# Model saving
torch.save(model.state_dict(), 'multimodal_embedding_model.pth')
# Example generation
model_path = 'multimodal_embedding_model.pth'
generate_example(model_path, image_dir, caption_file)Epoch 1/3: 15%|█▍ | 147/1012 [00:16<01:36, 8.96it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 1/3: 100%|██████████| 1012/1012 [01:53<00:00, 8.90it/s]Epoch 1/3 - Train Loss: 0.9618Epoch 1/3 - Validation Loss: 0.5212
Epoch 1: Saved best model with Validation Loss = 0.5212Epoch 2/3: 52%|█████▏ | 525/1012 [00:59<00:55, 8.84it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 2/3: 100%|██████████| 1012/1012 [01:54<00:00, 8.83it/s]Epoch 2/3 - Train Loss: 0.3393Epoch 2/3 - Validation Loss: 0.4240
Epoch 2: Saved best model with Validation Loss = 0.4240Epoch 3/3: 34%|███▍ | 347/1012 [00:39<01:15, 8.85it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 3/3: 100%|██████████| 1012/1012 [01:54<00:00, 8.83it/s]Epoch 3/3 - Train Loss: 0.2313Epoch 3/3 - Validation Loss: 0.3891
Epoch 3: Saved best model with Validation Loss = 0.3891
Image 0:
Top 3 Captions (Image -> Text):
- football players in red congratulate each other as crowds in red cheer behind. (prob: 0.9970)
- a man in black holds up an obama 08 sign. (prob: 0.0023)
- a large group of bicycles racing on the street (prob: 0.0004)
Caption: football players in red congratulate each other as crowds in red cheer behind.
Top 3 Images (Text -> Image):
- Image 0 (prob: 0.9983)
- Image 17 (prob: 0.0013)
- Image 2 (prob: 0.0001)
La atención cruzada modal se utiliza para modelar eficazmente las relaciones entre diferentes modalidades. Esto extiende la autoatención del ViT, permitiendo la interacción entre datos heterogéneos como imágenes y texto.
Diseño de atención entre modalidades
La atención cruzada modal tiene una estructura asimétrica que considera las características de cada modalidad.
class CrossModalAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.image_proj = nn.Linear(config.image_dim, config.hidden_dim)
self.text_proj = nn.Linear(config.text_dim, config.hidden_dim)
self.attention = nn.MultiheadAttention(config.hidden_dim, config.num_heads)
def forward(self, image_features, text_features):
image_proj = self.image_proj(image_features)
text_proj = self.text_proj(text_features)
attn_output, _ = self.attention(text_proj, image_proj, image_proj)
return attn_outputProyecta las características de imagen y texto a un espacio latente común, luego aprende la relación entre las dos modalidades mediante el mecanismo de atención multi-cabezal. Las características del texto se utilizan como consulta, mientras que las características de la imagen se usan como clave y valor para que el texto preste atención a las partes relevantes de la imagen.
Patrón de atención asimétrica
Se utiliza un patrón de atención asimétrico para preservar las características únicas de cada modalidad mientras se logra un intercambio de información efectivo.
class HierarchicalCrossModalAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.local_image_attention = nn.MultiheadAttention(config.hidden_dim, config.num_heads)
self.local_text_attention = nn.MultiheadAttention(config.hidden_dim, config.num_heads)
self.image_to_text_attention = CrossModalAttention(config)
self.text_to_image_attention = CrossModalAttention(config)
self.output_layer = nn.Linear(config.hidden_dim * 2, config.hidden_dim)
def forward(self, image_features, text_features):
local_image = self.local_image_attention(image_features, image_features, image_features)[0]
local_text = self.local_text_attention(text_features, text_features, text_features)[0]
image_attended_text = self.image_to_text_attention(image_features, local_text)
text_attended_image = self.text_to_image_attention(text_features, local_image)
combined_features = torch.cat([image_attended_text, text_attended_image], dim=-1)
output = self.output_layer(combined_features)
return outputAquí se realizan atenciones bidireccionales por separado, de texto a imagen e imagen a texto. Esto permite que cada modalidad pueda centrarse selectivamente en la información relevante de la otra modalidad.
Estructura de atención jerárquica
Para capturar relaciones multimodales complejas, se organizan varias capas de atención de manera jerárquica. En las capas inferiores, se procesan características locales dentro de cada modalidad, mientras que en las capas superiores se modelan las relaciones globales entre modalidades. Esta estructura jerárquica desempeña un papel clave en modelos como GPT-4V y Gemini.
class EnhancedMultimodalEmbedding_no_p(MultimodalEmbedding):
def forward(self, image, input_ids, attention_mask):
image_features = self.encode_image(image)
text_features = self.encode_text(input_ids, attention_mask)
image_features = self.image_preserve(image_features)
text_features = self.text_preserve(text_features)
combined_features = self.cross_modal_attention(image_features, text_features)
combined_features = combined_features / combined_features.norm(dim=-1, keepdim=True)
logit_scale = self.logit_scale.exp()
logits = logit_scale * combined_features @ combined_features.t()
return logitsimport torch
from torchvision import models, transforms
from torch.utils.data import Dataset, DataLoader
from collections import namedtuple
from dldna.chapter_10.crossmodal_attention import Flickr8kDataset, CrossModalEmbedding, train_crossmodal_embedding, generate_example
# Configuration
config = namedtuple('Config', ['embedding_dim', 'image_dim', 'text_dim', 'hidden_dim', 'num_heads'])(
embedding_dim=512, # Output embedding dimension
image_dim=512, # ResNet18 image encoder output dimension
text_dim=512, # Text feature (768 from BERT -> 512 after projection)
hidden_dim=512, # Cross-modal attention internal hidden dimension
num_heads=8 # Number of multi-head attention heads
)
# Data transformation setup
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# Dataset and DataLoader setup
image_dir = './data/flickr8k/Images' # Change to the actual path
caption_file = './data/flickr8k/captions.txt' # Change to the actual path
dataset = Flickr8kDataset(image_dir, caption_file, transform=transform)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4, pin_memory=True)
# Model initialization
model = CrossModalEmbedding(config)
# Model training
train_crossmodal_embedding(model, train_loader, val_loader, num_epochs=3)
# Model saving
torch.save(model.state_dict(), 'crossmodal_embedding_model.pth')Epoch 1/3: 4%|▍ | 40/1012 [00:04<01:41, 9.53it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 1/3: 100%|██████████| 1012/1012 [01:47<00:00, 9.41it/s]Epoch 1/3 - Train Loss: 0.9663Epoch 1/3 - Validation Loss: 0.5378Epoch 2/3: 58%|█████▊ | 582/1012 [01:02<00:45, 9.36it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 2/3: 100%|██████████| 1012/1012 [01:48<00:00, 9.31it/s]Epoch 2/3 - Train Loss: 0.3381Epoch 2/3 - Validation Loss: 0.4452Epoch 3/3: 0%| | 4/1012 [00:00<02:27, 6.82it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 3/3: 100%|██████████| 1012/1012 [01:48<00:00, 9.35it/s]Epoch 3/3 - Train Loss: 0.2288Epoch 3/3 - Validation Loss: 0.3743# Example generation
model_path = 'crossmodal_embedding_model.pth'
generate_example(model_path, image_dir, caption_file)Image 0:
Top 3 Captions (Image -> Text):
- two people walk out onto the desert sand. (prob: 0.9862)
- a man takes a picture of him and his friend with his phone. (prob: 0.0092)
- the little boy wearing the blue shirt is putting dirt in his mouth. (prob: 0.0013)
Caption: two people walk out onto the desert sand.
Top 3 Images (Text -> Image):
- Image 0 (prob: 0.9898)
- Image 2 (prob: 0.0089)
- Image 4 (prob: 0.0005)
Perceiver es una arquitectura multimodal propuesta por DeepMind en 2021. Resuelve el problema de la complejidad cuadrática de los transformadores tradicionales (donde la cantidad de cálculos aumenta al cuadrado con la longitud de la secuencia de entrada) y presenta una estructura que puede procesar eficazmente diversas modalidades (imágenes, texto, audio, nubes de puntos, etc.). Perceiver es particularmente beneficioso cuando el tamaño de los datos de entrada es muy grande (por ejemplo: imágenes de alta resolución, textos largos). En este capítulo se proporciona una descripción general de la arquitectura y se omite el ejemplo. El código es un ejemplo ilustrativo para la explicación.
Idea clave de Perceiver
Perceiver se basa en las siguientes ideas:
Perceiver utiliza un conjunto de vectores latentes de tamaño fijo, independientemente de la longitud de la secuencia de entrada. Estos vectores latentes desempeñan el papel de comprimir y representar la información de los datos de entrada, resumiendo grandes cantidades de información de entrada en un número reducido de vectores latentes, similar a un cuello de botella. Por lo tanto, sin importar cuán grande sea el tamaño de los datos de entrada (por ejemplo: 10,000 tokens), el número de vectores latentes permanece fijo (por ejemplo: 256), lo que permite reducir significativamente la complejidad computacional y el uso de memoria.
class Perceiver(nn.Module):
def __init__(self, ..., num_latents=256, latent_dim=512, ...):
super().__init__()
# Latent vector initialization (key!)
self.latents = nn.Parameter(torch.randn(num_latents, latent_dim))
# ...En el código anterior, self.latents representa directamente ese vector latente. Se define como un parámetro aprendible mediante nn.Parameter.
Perceiver no utiliza métodos de procesamiento especializados para modalidades de entrada específicas (como imágenes, texto, audio), por ejemplo CNN o RNN. En su lugar, cada modalidad pasa por un preprocesamiento simple (por ejemplo, parches de imagen, tokenización de texto) y se convierte en una forma común (secuencia de vectores). A partir de este punto, se utiliza la misma arquitectura basada en transformadores (Cross-Attention, Self-Attention) para procesar los datos, independientemente del tipo de modalidad. Esto permite un manejo flexible de diversas modalidades y facilita la adición de nuevas modalidades.
Perceiver utiliza múltiples capas de autoatención (self-attention) para actualizar gradualmente los vectores latentes. En cada capa, los vectores latentes intercambian información entre sí y aprenden patrones complejos en los datos de entrada. Los vectores latentes que inicialmente representaban características simples, evolucionan a medida que pasan por múltiples capas, llegando a expresar significados más abstractos y de alto nivel.
Funcionamiento de Perceiver (ejemplo de código simplificado)
import torch
import torch.nn as nn
class Perceiver(nn.Module):
def __init__(self,
input_channels=3, # Input channels (e.g., RGB image)
input_axis=2, # Input dimension (image=2, video=3)
num_latents=256, # Number of latent vectors
latent_dim=512, # Latent vector dimension
num_heads=8, # Number of attention heads
depth=6): # Model depth (number of self-attention layers)
super().__init__()
# 1. Latent vector initialization (key!)
self.latents = nn.Parameter(torch.randn(num_latents, latent_dim))
# 2. Input projection (matches input dimension to latent dimension)
self.input_proj = nn.Linear(input_dim, latent_dim)
# 3. Cross-Attention (learns relationships between input and latent vectors)
# self.cross_attention = nn.MultiheadAttention(latent_dim, num_heads, batch_first=True)
# 4. Self-Attention (learns relationships between latent vectors) - repeated multiple times
self.self_attention_layers = nn.ModuleList([
nn.MultiheadAttention(latent_dim, num_heads, batch_first=True)
for _ in range(depth)
])
def forward(self, x): # x: Input data (image, text, ...)
batch_size = x.shape[0]
# 1. Input projection
x = self.input_proj(x)
# 2. Latent vector replication (for each item in the batch)
latents = self.latents.unsqueeze(0).expand(batch_size, -1, -1) # (B, num_latents, latent_dim)
# 3. (Optional) Cross-attention (between input and latent vectors)
# latents, _ = self.cross_attention(latents, x, x) # query, key, value
# 4. Self-attention (between latent vectors) - repeated multiple times
for layer in self.self_attention_layers:
latents, _ = layer(latents, latents, latents) # query, key, value
return latents # Return the processed latent vectorsVentajas y desventajas del Perceiver
El Perceiver tiene eficiencia, ya que su complejidad de cálculo es casi constante independientemente del tamaño de entrada, y ofrece flexibilidad al poder procesar diferentes modalidades de la misma manera. Además, la escalabilidad para agregar nuevas modalidades fácilmente también es una ventaja del Perceiver. Sin embargo, el Perceiver sigue siendo complejo en su estructura debido a que se basa en transformers, y puede volverse muy grande si las dimensiones de los vectores latentes y el número de capas son grandes, lo cual es una desventaja. Además, en tareas específicas como la clasificación de imágenes, el rendimiento del Perceiver puede ser inferior al de modelos especializados para esa tarea, como CNN.
Perceiver IO
Perceiver IO, un estudio posterior al Perceiver, propuso un método que procesa tanto entradas como salidas a través de vectores latentes. Esto permitió manejar flexiblemente diferentes formas de salida (clasificación, regresión, generación de secuencias, etc.). Se considera que Perceiver IO es un modelo más general y poderoso en comparación con el Perceiver.
Aquí comenzamos con la estructura básica de la atención cruzada, y gradualmente añadimos mecanismos mientras comparamos la posibilidad de entrenamiento y el rendimiento. A través de esto, comprendemos los problemas que surgen en el aprendizaje multimodal y examinamos métodos prácticos para abordarlos.
Cuando se diseña el mecanismo de atención cruzada, es muy común y recomendable ir aumentando gradualmente la complejidad, como se describe en esta sección. Este enfoque, conocido como estudio de ablación (Ablation study), es efectivo para determinar la importancia de cada componente del mecanismo y para identificar los elementos clave que contribuyen al rendimiento final del modelo. Muchos artículos que proponen nuevas arquitecturas utilizan este enfoque. Además, discutir no solo el rendimiento final sino también los problemas de estabilidad durante el entrenamiento es muy importante desde una perspectiva práctica.
Métodos de entrenamiento comparativo
El experimento utiliza el conjunto de datos flickr8k, que tiene dos entradas: texto e imagen, para entrenar la similitud mutua. Durante el entrenamiento, hay varias versiones de atención cruzada, y cada versión es más compleja que la anterior. Se añade un mecanismo de atención cruzada en cada versión y se realiza el entrenamiento para compararlo. Todos los entrenamientos utilizan los mismos hiperparámetros. El número de épocas de entrenamiento está fijado en 5.
Estructura del ejemplo
El ejemplo tiene la siguiente estructura.
chatper_10/mm
├── cat_resized.png
├── cross_attention
│ ├── v0.py
│ ├── v1.py
│ ├── v2.p
│ ├── v3.py
│ .... (continúa existiendo)
├── train_multimodal.py
└── evaluate_models.pyLa carpeta cross_attention contiene versiones de complejidad creciente de la atención cruzada, desde v1 hasta v11. train_mulimodal.py genera dinámicamente la siguiente versión del modelo una vez que se completa un entrenamiento y continúa el proceso de entrenamiento. Durante el entrenamiento, se registran métricas como precisión, pérdida contrastiva y tiempo de ejecución para generar una tabla final de comparación. No es recomendable juzgar la viabilidad del entrenamiento solo por los valores de pérdida y precisión. Dada la naturaleza del aprendizaje contrastivo, la forma más sencilla de verificar si el modelo se ha entrenado correctamente es evaluándolo con datos que no estén presentes en el conjunto de entrenamiento. El archivo para evaluar el modelo en un escenario de zero-shot es evalute_models.py.
La imagen utilizada para la evaluación es la siguiente:

La evaluación se realiza midiendo la similitud entre la imagen y cinco textos.
test_captions = [
"A dog playing in the park",
"A cat sleeping on a couch",
"Children playing soccer",
"A sunset over the ocean",
"A person cooking in the kitchen"
]Si el modelo se ha entrenado correctamente, la segunda caption “A cat sleeping on a couch” debería tener la mayor similitud entre las cinco captions. La imagen utilizada no está presente en los datos de entrenamiento y corresponde a un caso típico de prueba zero-shot.
Asignación dinámica de cross-attention
La asignación dinámica se realiza a través de la versión de cross_attention.
from dldna.chapter_10.mm.cross_attention.v0 import CrossAttention as v0
from dldna.chapter_10.mm.cross_attention.v1 import CrossAttention as v1
# ... (import other versions) ...
from dldna.chapter_10.mm.cross_attention.v11 import CrossAttention as v11
def get_cross_attention(version, config=None):
if config is None:
config = {}
if version == 'v0':
return v0(**config)
elif version == 'v1':
return v1(**config)
# ... (other version conditions) ...
elif version == 'v11':
return v11(**config)
else:
raise ValueError(f"Invalid cross-attention version: {version}")
# ...
class ImageTextMatchingModel(nn.Module):
def __init__(self, image_encoder_dim=2048, text_encoder_dim=768, projection_dim=256):
super().__init__()
self.image_encoder = ImageEncoder(image_encoder_dim, projection_dim)
self.text_encoder = TextEncoder(text_encoder_dim, projection_dim)
# The CrossAttention module is dynamically assigned in main().
self.cross_attention = None # CrossAttention(projection_dim)
def forward(self, image, input_ids, attention_mask):
# ...
image_attended, text_attended = self.cross_attention(
image_features.unsqueeze(1),
text_features.unsqueeze(1)
)
# ...
# ...
def run_training(model_versions, ...):
# ...
for model_version in model_versions:
# ...
# Model initialization
model = ImageTextMatchingModel()
# Dynamically load the CrossAttention module
model.cross_attention = get_cross_attention(model_version, config=config)
# ...Esta sección implementa la lógica para cargar y aplicar dinámicamente diferentes versiones del módulo Cross-Attention. La función get_cross_attention recibe una versión en forma de cadena (v0, v1, …, v11) y devuelve una instancia de la clase CrossAttention correspondiente a esa versión. Dentro de la función run_training, se inicializa ImageTextMatchingModel para cada versión especificada en la lista model_versions, y se llama a la función get_cross_attention para asignar el módulo de Cross-Attention correspondiente a model.cross_attention.
Este enfoque de asignación dinámica aumenta la reutilizabilidad del código y facilita la gestión de experimentos. Al agregar una nueva versión de Cross-Attention, solo es necesario incluir esa versión en la función get_cross_attention, por lo que no se requiere modificar significativamente el código de entrenamiento. Además, a través de la lista model_versions en la función run_training, se puede controlar fácilmente qué versiones se entrenarán.
Cálculo de la pérdida Contrastive y bucle de entrenamiento
def contrastive_loss(logits):
labels = torch.arange(len(logits), device=logits.device)
loss_i = nn.CrossEntropyLoss()(logits, labels)
loss_t = nn.CrossEntropyLoss()(logits.t(), labels)
return (loss_i + loss_t) / 2
def train(model, train_loader, val_loader, epochs=10, lr=1e-4, model_version='v0'):
# ...
for epoch in range(epochs):
model.train()
total_loss = 0
# ...
for batch in tqdm(train_loader, ...):
images, input_ids, attention_mask = [x.to(device) for x in batch]
optimizer.zero_grad()
logits = model(images, input_ids, attention_mask)
loss = contrastive_loss(logits)
loss.backward()
optimizer.step()
total_loss += loss.item()
# ... (validation 및 지표 계산) ...Esta parte define el cálculo de la Pérdida Contrastiva (Contrastive Loss) utilizada en el entrenamiento del modelo y el bucle de entrenamiento. La función contrastive_loss toma como entrada las puntuaciones de similitud (logits) entre las imágenes y los textos, y calcula la pérdida contrastiva. En este caso, las etiquetas correctas corresponden a los elementos en la diagonal de los logits (es decir, los pares imagen-texto con el mismo índice), que se establecen en 1 (similares), mientras que el resto se establece en 0 (no similares) utilizando torch.arange. Se calcula tanto la Pérdida de Entropía Cruzada basada en la imagen (loss_i) como la basada en el texto (loss_t), y se utiliza el promedio de ambas como la pérdida final.
Método de entrenamiento: Adición de mecanismos
Comenzaremos desde la estructura de atención más simple, añadiendo funciones una por una para realizar pruebas. Llamaremos a estas funciones adicionales “mecanismos”. Observaremos cómo cada mecanismo afecta al diseño de la atención multimodal a medida que se añade. Primero revisaremos parte del código de entrenamiento y luego veremos los resultados del entrenamiento. Después, analizaremos qué mecanismos en cada atención cruzada modal influyeron en el éxito o fracaso del entrenamiento.
A continuación se presenta el código de entrenamiento. Durante el entrenamiento, cada modelo se guarda como model_final_{versión}.pth. Se utiliza este modelo guardado para realizar la evaluación.
from dldna.chapter_10.mm.train_multimodal import run_training
# model_versions = ['v0', 'v1'] # List of model versions to train
model_versions = ['v0', 'v1', 'v2', 'v3', 'v4', 'v5', 'v6', 'v7', 'v8', 'v9', 'v10_1', 'v10_2', 'v10_3', 'v10_4', 'v10_5', 'v10_6', 'v11']
epochs = 5
lr = 1e-4
# Dataset
image_dir = './data/flickr8k/Images' # Change to the actual path
caption_file = './data/flickr8k/captions.txt' # Change to the actual path
results_df = run_training(model_versions, epochs=epochs, lr=lr, image_dir=image_dir, caption_file=caption_file) # Train multiple versions
# Print results
print("\nTraining Results:")
# Print results in Markdown table format
print(results_df.to_markdown(index=False))Evaluamos con el modelo.
from dldna.chapter_10.mm.evaluate_models import evaluate_all_models
# Test captions (fixed)
test_captions = [
"A dog playing in the park",
"A cat sleeping on a couch",
"Children playing soccer",
"A sunset over the ocean",
"A person cooking in the kitchen"
]
# Run model evaluation
image_path = './cat_resized.png'
model_dir = '.'
model_versions = ['v0', 'v1', 'v2', 'v3', 'v4', 'v5', 'v6', 'v7', 'v8', 'v9', 'v10_1', 'v10_2', 'v10_3', 'v10_4', 'v10_5', 'v10_6', 'v11']
results_df = evaluate_all_models(model_dir, image_path, test_captions, model_versions)
# Print results (Markdown table)
print(results_df.to_markdown(index=False))
# Print results (detailed)
for _, row in results_df.iterrows():
print(f"\nModel: {row['model_version']}")
print(f" Best Caption: {row['best_caption']}")
print(f" Trained Well: {row['trained_well']}")
print(f" Similarity Ratio: {row['similarity_ratio']}")
print(f" Similarity Gap: {row['similarity_gap']}")
print(" All Similarities:")
for caption, sim in zip(test_captions, row['all_similarities']):
print(f" - {caption:<30}: {sim}")| model_version | best_caption | all_similarities | similarity_ratio | similarity_gap | trained_well | similarity_ratio_rank |
|---|---|---|---|---|---|---|
| v0 | Un gato durmiendo en un sofá | [‘5.322’, ‘15.477’, ‘-4.509’, ‘-6.609’, ‘2.107’] | 2.908 | 10.155 | True | 1 |
| v1 | Un gato durmiendo en un sofá | [‘3.117’, ‘18.174’, ‘-6.475’, ‘-1.825’, ‘8.705’] | 2.088 | 9.469 | True | 3 |
| v2 | Un gato durmiendo en un sofá | [‘3.085’, ‘12.541’, ‘-4.252’, ‘0.924’, ‘6.849’] | 1.831 | 5.692 | True | 5 |
| v3 | Niños jugando fútbol | [‘34.882’, ‘34.882’, ‘34.882’, ‘34.882’, ‘34.882’] | 1 | 0 | False | 14 |
| v4 | Un gato durmiendo en un sofá | [‘7.385’, ‘8.301’, ‘-1.038’, ‘-6.262’, ‘1.240’] | 1.124 | 0.915 | True | 12 |
| v5 | Niños jugando fútbol | [‘27.357’, ‘27.357’, ‘27.357’, ‘27.357’, ‘27.357’] | 1 | 0 | True | 14 |
| v10_2 | Un gato durmiendo en un sofá | [‘17.720’, ‘17.720’, ‘17.720’, ‘17.720’, ‘17.720’] | 1 | 0 | True | 14 |
| v10_3 | Un gato durmiendo en un sofá | [‘0.516’, ‘1.479’, ‘-0.941’, ‘-0.106’, ‘0.694’] | 2.132 | 0.786 | True | 2 |
| v10_4 | Un gato durmiendo en un sofá | [‘5.913’, ‘10.334’, ‘-5.989’, ‘-1.024’, ‘5.151’] | 1.748 | 4.421 | True | 6 |
| v10_5 | Un gato durmiendo en un sofá | [‘6.601’, ‘9.990’, ‘-5.984’, ‘-2.988’, ‘-0.070’] | 1.513 | 3.389 | True | 8 |
| v10_6 | Un perro jugando en el parque | [‘33.967’, ‘33.302’, ‘31.580’, ‘32.710’, ‘31.384’] | 1.02 | 0.665 | False | 13 |
| v11 | Un gato durmiendo en un sofá | [‘11.315’, ‘15.491’, ‘-10.428’, ‘-0.004’, ‘10.014’] | 1.369 | 4.175 | True | 11 |
| v10_6 | Un perro jugando en el parque | [‘33.967’, ‘33.302’, ‘31.580’, ‘32.710’, ‘31.384’] | 1.02 | 0.665 | False | 13 |
Basándonos en los resultados de este experimento, podemos analizar los resultados de entrenamiento para cada versión de atención cruzada y resumir las causas del éxito/fallo en el entrenamiento de la siguiente manera. Here’s the translated version:
| Version | Name | Description | Training Result |
|---|---|---|---|
| v1 | Basic Attention | Simple attention mechanism using dot product between image and text features. | Success |
| v2_1 | Normalized Features | Normalizes both image and text features before applying attention. | Failure (Vanishing Gradients) |
| v2_2 | Residual Connection | Adds residual connection to the attention output, maintaining the original feature information. | Success |
| v3 | Feature Projection | Projects image and text features into a common space using linear layers. | Failure (Loss of Feature Information) |
| v4_1 | Modality-Specific Projections | Applies separate projections for images and texts to preserve modality-specific characteristics. | Failure (Too Complex, Overfitting) |
| v4_2 | Shared Projection Layer | Uses a single shared projection layer for both modalities to reduce complexity. | Success |
| v5 | Scaled Dot-Product Attention | Applies scaling factor in dot-product attention to prevent large values during softmax computation. | Success |
| v6 | Multi-Head Attention | Introduces multi-head mechanism, allowing the model to capture multiple aspects of the relationship between modalities. | Success |
| v7_1 | Relative Positional Encoding | Adds relative positional encodings to account for sequential information in text features. | Failure (Unstable Training) |
| v7_2 | Absolute Positional Encoding | Uses absolute positional encodings instead. | Success |
| v8 | Layer Normalization | Applies layer normalization after attention to stabilize training and improve performance. | Success |
| v9_1 | Adaptive Attention Weights | Introduces adaptive attention weights for each modality, controlled by learnable parameters. | Failure (Training Divergence) |
| v9_2 | Softmax Temperature Scaling | Applies temperature scaling in the softmax function to control the sharpness of attention distribution. | Success |
| v10 | Cross-Modality Attention | Allows bidirectional attention between images and texts, enhancing cross-modality interaction. | Success |
| v11_1 | Attention with Dropout | Adds dropout after attention to prevent overfitting and improve generalization. | Success |
| v11_2 | Gated Attention Mechanism | Introduces a gating mechanism to control the flow of information between modalities. | Failure (Training Instability) |
| v12 | Dual-Stream Attention | Maintains separate attention streams for each modality and fuses them at the end. | Success |
| v13_1 | Hierarchical Feature Fusion | Fuses features at multiple levels to capture both local and global information. | Failure (Complexity) |
| v13_2 | Weighted Feature Fusion | Uses learnable weights for weighted fusion of attention outputs. | Success |
| v14 | Contextual Attention | Adds context vectors to the attention mechanism to provide more contextual information. | Success |
| v15_1 | Transformer-based Attention | Replaces traditional attention with transformer blocks for better modeling of long-range dependencies. | Failure (Resource Intensive) |
| v15_2 | Lightweight Transformer | Optimizes the transformer architecture to reduce computational cost while maintaining performance. | Success |
This table provides a comprehensive overview of the different versions and their outcomes, highlighting successful and unsuccessful attempts in developing an attention mechanism for multi-modal data. #### 10.4.4.3 Explicación por estructura de atención
1. v0: Atención bidireccional independiente - estructura básica
v0 implementa la forma más básica de Cross-Modal Attention. Calcula la atención de manera independiente para imagen y texto, sin usar ninguna normalización o transformación adicional fuera del producto interno escalado (Scaled Dot-Product Attention).
import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.scale = dim ** -0.5
def forward(self, image_features, text_features):
# Image -> Text attention
attn_i2t = torch.matmul(image_features, text_features.transpose(-2, -1)) * self.scale
attn_i2t = attn_i2t.softmax(dim=-1)
image_attended = torch.matmul(attn_i2t, text_features)
# Text -> Image attention
attn_t2i = torch.matmul(text_features, image_features.transpose(-2, -1)) * self.scale
attn_t2i = attn_t2i.softmax(dim=-1)
text_attended = torch.matmul(attn_t2i, image_features)
return image_attended, text_attendedv0 es sensible a los cambios de escala de las características de entrada porque no tiene un proceso de normalización separado. Si la escala de los datos de entrada cambia significativamente durante el proceso de aprendizaje, los pesos de atención pueden volverse inestables y el entrenamiento puede no realizarse correctamente.
2. v2: Atención compartida + Normalización por Capa
v2 es una versión que estabiliza la escala de las características aplicando Layer Normalization (LN) a las características de entrada, a diferencia de v1. Aunque v1 utilizaba la misma matriz de atención (matriz de pesos) y su transpuesta para calcular la atención imagen→texto, texto→imagen, tenía la desventaja de ser sensible a la escala de entrada.
import torch
import torch.nn as nn
import torch.nn.functional as F
# Co-attention + added LN
class CrossAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.scale = dim ** -0.5
self.norm = nn.LayerNorm(dim) # Use a single LayerNorm
def forward(self, image_features, text_features):
# Input normalization
image_norm = self.norm(image_features)
text_norm = self.norm(text_features)
# Simple attention calculation
attn = torch.matmul(image_norm, text_norm.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# Bidirectional feature fusion (without residual connection)
image_out = torch.matmul(attn, text_norm)
text_out = torch.matmul(attn.transpose(-2, -1), image_norm)
return image_out, text_outimage_norm = self.norm(image_features) y text_norm = self.norm(text_features) aplican la Normalización de Capa (Layer Normalization) a las características de entrada. La Normalización de Capa realiza la normalización de forma independiente para cada muestra (cada imagen o texto en el minibatch). Es decir, calcula la media y la varianza del vector de características de cada muestra para convertirlas en 0 y 1. Esto ayuda a estabilizar el aprendizaje al prevenir que los pesos de atención diverjan incluso si la escala de las características de entrada cambia significativamente.
Sin embargo, aún existen limitaciones. v2 resolvió el problema de escala de entrada mediante la Normalización de Capa pero utiliza la misma matriz de atención para la atención imagen→texto y texto→imagen. Esto puede no reflejar adecuadamente la relación asimétrica entre las dos modalidades. Generar texto a partir de una imagen y generar imágenes a partir de un texto pueden tener complejidades diferentes. Tratar esto con el mismo mecanismo de atención puede ser ineficiente.
3. v3: v2 + conexión residual (Residual Connection) - caso de fracaso
Después del diseño arquitectónico del modelo ResNet, la conexión residual se ha utilizado como una práctica común para mitigar el problema de desvanecimiento de gradientes (Gradient Vanishing) que puede ocurrir a medida que las redes se vuelven más profundas y para permitir el aprendizaje efectivo de redes más profundas. Sin embargo, en este experimento, la conexión residual resultó ser una causa de fracaso al reducir el rendimiento.
Esta es una observación muy importante.
import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.scale = dim ** -0.5
self.norm = nn.LayerNorm(dim) # Use a single LayerNorm
def forward(self, image_features, text_features):
# Input normalization
image_norm = self.norm(image_features)
text_norm = self.norm(text_features)
# Simple attention calculation
attn = torch.matmul(image_norm, text_norm.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# Bidirectional feature fusion
image_attended = torch.matmul(attn, text_norm)
text_attended = torch.matmul(attn.transpose(-2, -1), image_norm)
# Add residual connection
image_out = image_features + image_attended
text_out = text_features + text_attended
return image_out, text_outGeneralmente, las conexiones residuales son efectivas para resolver el problema de que la red se hace más difícil de entrenar a medida que aumenta su profundidad. Sin embargo, en v3, esto resultó en una disminución del rendimiento debido a las siguientes razones.
Red relativa poco profunda: El modelo v3 tiene una estructura de red relativamente poco profunda. Las conexiones residuales ayudan significativamente a mitigar el problema de la desaparición del gradiente en redes profundas, pero su efecto es mínimo en redes poco profundas y pueden incluso interrumpir el flujo de información.
Preservación excesiva de las características originales: El núcleo de la Atención Multimodal (Cross-Modal Attention) es generar nuevas características a través de la interacción entre dos modalidades diferentes, imagen y texto. Sin embargo, en v3, al sumar directamente los vectores de características originales al resultado de las operaciones de atención, se diluyó la información importante obtenida mediante el mecanismo de atención y se obstaculizó la generación de características a través de la interacción entre las dos modalidades. En otras palabras, en lugar de aprender nueva información, el modelo se centró más en mantener la información existente.
Los resultados experimentales de v3 brindan una importante lección: las conexiones residuales no son una solución universal que siempre mejore el rendimiento. Las conexiones residuales deben utilizarse con cuidado, considerando la profundidad de la red, el lugar de aplicación y las características del problema. v3 es un ejemplo típico de fracaso debido al uso inadecuado de las conexiones residuales, lo que resultó en una disminución del rendimiento.
4. v8: Atención multi-cabeza independiente
v8 introdujo cambios importantes para resolver los problemas de la versión anterior (v7) y mejorar el rendimiento de la Atención Multimodal. En particular, separó la atención imagen→texto y texto→imagen en atenciones multi-cabeza (Multi-Head Attention) independientes. Además, aplicó Normalización de Capa (Layer Normalization) no solo a las entradas sino también a las salidas de las operaciones de atención, lo que mejoró aún más la estabilidad del entrenamiento.
import torch
import torch.nn as nn
import torch.nn.functional as F
# v8 - Independent multi-head
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
self.norm = nn.LayerNorm(dim)
# Projections for multi-head attention
self.to_q = nn.Linear(dim, dim)
self.to_k = nn.Linear(dim, dim)
self.to_v = nn.Linear(dim, dim)
# Output projection
self.to_out = nn.Linear(dim, dim)
# Add output normalization
self.out_norm = nn.LayerNorm(dim)
def forward(self, image_features, text_features):
B, N_i, _ = image_features.shape
_, N_t, _ = text_features.shape
H = self.num_heads
# Input normalization
image_norm = self.norm(image_features)
text_norm = self.norm(text_features)
def split_heads(x):
return x.reshape(B, -1, H, self.head_dim).transpose(1, 2)
# Image -> Text direction attention
q_img = split_heads(self.to_q(image_norm))
k_txt = split_heads(self.to_k(text_norm))
v_txt = split_heads(self.to_v(text_norm))
attn_i2t = torch.matmul(q_img, k_txt.transpose(-2, -1)) * self.scale
attn_i2t = attn_i2t.softmax(dim=-1)
image_attended = torch.matmul(attn_i2t, v_txt)
# Text -> Image direction attention
q_txt = split_heads(self.to_q(text_norm))
k_img = split_heads(self.to_k(image_norm))
v_img = split_heads(self.to_v(image_norm))
attn_t2i = torch.matmul(q_txt, k_img.transpose(-2, -1)) * self.scale
attn_t2i = attn_t2i.softmax(dim=-1)
text_attended = torch.matmul(attn_t2i, v_img)
# Combine heads and output projection
image_attended = image_attended.transpose(1, 2).reshape(B, N_i, -1)
text_attended = text_attended.transpose(1, 2).reshape(B, N_t, -1)
image_out = self.out_norm(self.to_out(image_attended))
text_out = self.out_norm(self.to_out(text_attended))
return image_out, text_outv7 también introdujo la atención multi-cabeza, pero aún utilizaba las mismas transformaciones Q, K, V para la atención imagen→texto y texto→imagen. Es decir, dado que todas las cabezas compartían las mismas matrices Q, K, V, había restricciones en el aprendizaje de características distintivas por cada cabeza, lo cual limitaba la capacidad expresiva del modelo. v8 abordó estos problemas aplicando transformaciones Q, K, V independientes para cada dirección (imagen→texto, texto→imagen) y para cada cabeza, permitiendo que el modelo aprendiera representaciones de características mucho más flexibles y ricas.
5. v9: v8 + Pre-LN + FFN (FFN con puerta + dropout)
v9 se basa en la estructura de v8 e introduce tres mecanismos importantes para mejorar aún más la estabilidad del entrenamiento y el rendimiento. Estos son: Normalización de Capa Previo (Pre-Layer Normalization), Red Neuronal Feed-Forward con Puerta (Feed-Forward Network, FFN) y dropout (Dropout).
import torch
import torch.nn as nn
import torch.nn.functional as F
# v9 - Dropout before gated FFN, pass through norm at the end -> trainable
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8, dropout=0.1, ff_dim=None):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
ff_dim = ff_dim or dim * 4
# Normalization layers for Pre-LN
self.attn_norm = nn.LayerNorm(dim)
self.ff_norm = nn.LayerNorm(dim)
# Projections for multi-head attention
self.to_q = nn.Linear(dim, dim)
self.to_k = nn.Linear(dim, dim)
self.to_v = nn.Linear(dim, dim)
# Output projection
self.to_out = nn.Linear(dim, dim)
# Dropout
self.dropout = nn.Dropout(dropout)
# Gated feedforward network
self.ff_gate = nn.Sequential(
nn.Linear(dim, ff_dim),
nn.GELU(),
nn.Dropout(dropout)
)
self.ff_value = nn.Sequential(
nn.Linear(dim, ff_dim),
nn.GELU(),
nn.Dropout(dropout)
)
self.ff_out = nn.Linear(ff_dim, dim)
def forward(self, image_features, text_features):
B, N_i, _ = image_features.shape
_, N_t, _ = text_features.shape
H = self.num_heads
def split_heads(x):
return x.reshape(B, -1, H, self.head_dim).transpose(1, 2)
# Pre-LN: Normalize before attention
image_norm = self.attn_norm(image_features)
text_norm = self.attn_norm(text_features)
# Image -> Text direction attention
q_img = split_heads(self.to_q(image_norm))
k_txt = split_heads(self.to_k(text_norm))
v_txt = split_heads(self.to_v(text_norm))
attn_i2t = torch.matmul(q_img, k_txt.transpose(-2, -1)) * self.scale
attn_i2t = attn_i2t.softmax(dim=-1)
attn_i2t = self.dropout(attn_i2t) # Apply dropout to attention weights
image_attended = torch.matmul(attn_i2t, v_txt)
# Text -> Image direction attention
q_txt = split_heads(self.to_q(text_norm))
k_img = split_heads(self.to_k(image_norm))
v_img = split_heads(self.to_v(image_norm))
attn_t2i = torch.matmul(q_txt, k_img.transpose(-2, -1)) * self.scale
attn_t2i = attn_t2i.softmax(dim=-1)
attn_t2i = self.dropout(attn_t2i) # Apply dropout to attention weights
text_attended = torch.matmul(attn_t2i, v_img)
# Combine heads and output projection
image_attended = image_attended.transpose(1, 2).reshape(B, N_i, -1)
text_attended = text_attended.transpose(1, 2).reshape(B, N_t, -1)
# Output projection and dropout
image_attended = self.dropout(self.to_out(image_attended))
text_attended = self.dropout(self.to_out(text_attended))
# Residual connection - connecting the original image features makes training impossible.
# image_attended = image_attended + image_features
# text_attended = text_attended + text_features
# Pre-LN: Normalize before FFN
image_ff = self.ff_norm(image_attended)
text_ff = self.ff_norm(text_attended)
# Gated feedforward processing
def apply_ff(x):
gate = self.ff_gate(x)
value = self.ff_value(x)
return self.dropout(self.ff_out(gate * value))
# FFN output and residual connection - this type of residual connection is possible.
image_out = apply_ff(image_ff) + image_attended
text_out = apply_ff(text_ff) + text_attended
return image_out, text_outPre-Layer Normalization: v8 aplicaba Layer Normalization después de las operaciones de atención (Post-LN), pero v9 lo aplica antes (Pre-LN). self.image_norm_q, self.image_norm_k, …, self.text_norm_v son ejemplos de esto. Pre-LN es más estable durante el entrenamiento que Post-LN y no requiere un calentamiento separado, por lo que se utiliza ampliamente en modelos basados en Transformer recientes.
Feed-Forward Network (FFN) con puerta: v8 añade una FFN después de las operaciones de atención para mejorar la no linealidad y el poder de representación del modelo.
self.image_ffn y self.text_ffn definen la FFN. La FFN consta de dos capas lineales (Linear Layer) con una función de activación GELU (Gaussian Error Linear Unit) entre ellas, seguida de un dropout.self.image_ffn_norm, self.text_ffn_norm). A diferencia de v3, se aplica después de pasar por la FFN, lo que permite combinar información después del procesamiento no lineal, mejorando el flujo de información y contribuyendo a un mejor rendimiento.Dropout: self.dropout define el dropout aplicado a los pesos de atención y dentro de la FFN. El dropout es una técnica efectiva de regularización que desactiva aleatoriamente neuronas durante el entrenamiento para prevenir el sobreajuste del modelo.
Efecto de los mecanismos añadidos
v9 ha mejorado significativamente el rendimiento de Cross-Modal Attention a través de la combinación de estas técnicas, convirtiéndose en la base para versiones posteriores.
v0, v1 (estructura básica): v0 y v1, que solo utilizan atención simple sin normalización, se entrenaron con éxito. Sin embargo, en el caso de v1, aunque se entrenó, mostró una mayor similitud a las leyendas relacionadas con “gatos” tanto en el conjunto de datos de entrenamiento como en el de validación. Esto sugiere la importancia de la normalización.
v2 (LayerNorm): v2, que aplica LayerNorm a la entrada, se entrenó con éxito. Esto demuestra que estabilizar la escala de las características de entrada es importante.
v3 (conexión residual): v3, que añade conexión residual a v2, falló en el entrenamiento. Esto sugiere que la conexión residual no siempre ayuda en el aprendizaje multimodal. La conexión residual puede mantener excesivamente las características originales, lo cual puede interferir con el aprendizaje de la interacción entre dos modalidades.
v4 (proyección): v4, que añade transformaciones lineales independientes (proyecciones) a cada modalidad, se entrenó con éxito. Esto sugiere que es importante transformar adecuadamente los espacios de características de cada modalidad.
v7 (multicabezal compartido): v7, que extiende la matriz de atención compartida a multicabezales, falló en el entrenamiento. Se interpreta que esto se debe a que cada cabeza no reflejó adecuadamente las características de diferentes modalidades.
v8 (multicabezal independiente): v8, que utiliza atención multicabezal independiente para cada dirección (imagen→texto, texto→imagen) y aplica LayerNorm separado en la entrada y salida, se entrenó con éxito. Esto demuestra que es importante preservar las características de cada modalidad mientras intercambia información.
v10_1 (Q/K/V por modalidad): v10_1, basado en v9 y que introduce transformaciones Q/K/V especializadas para cada modalidad, tuvo un entrenamiento inestable. Se espera que esto se deba a la complejidad adicional introducida.
v10_4 (atención multiconsulta): v10_4, que mantiene las consultas (Q) independientes pero comparte claves (K) y valores (V) en atención multiconsulta, se entrenó con éxito. Se interpreta que esto reduce el número de parámetros mientras permite un intercambio eficiente de información, mejorando el rendimiento general.
v10_5 (multicabezal jerárquico): v10_5, que introduce una estructura jerárquica en tres etapas y aplica atención multicabezal independiente en cada nivel antes de fusionar los resultados con pesos, se entrenó con éxito. Se analiza que esto integra gradualmente las características y aprovecha eficazmente la información de cada nivel para mejorar el rendimiento.
v10_6 (multicabezal de aprendizaje contrastivo): v10_6, que añade una capa de proyección separada para el aprendizaje contrastivo y entrena sumando directamente la información de similitud a las características originales, tuvo un entrenamiento inestable. Se sospecha que la información de similitud puede distorsionar las características originales, interfiriendo con el aprendizaje.
v11 (multiconsulta + fusión jerárquica): v11, que combina las ventajas de la atención multiconsulta (v10_4) y la fusión jerárquica (v10_5), se entrenó con éxito. Esto significa que logró un aprendizaje estable al aprovechar tanto la eficiencia de parámetros como la integración gradual de características.
Conclusión
A través de este experimento de eliminación, podemos llegar a las siguientes conclusiones. 1. Importancia de la normalización: Aplicar LayerNorm a las características de entrada es muy importante para la estabilidad del entrenamiento (v2). 2. Dualidad de las conexiones residuales: Las conexiones residuales son un mecanismo útil, pero en las etapas iniciales del aprendizaje multimodal pueden ser perjudiciales (v3). Mantener excesivamente las características originales puede interferir con el aprendizaje de la interacción entre los dos modos. 3. Transformación independiente de características: Aplicar transformaciones lineales (proyecciones) independientes a cada modo puede mejorar el rendimiento (v4). 4. Atención multi-cabeza: Al usar atención multi-cabeza, cada cabeza debe configurarse independientemente para reflejar las características de diferentes modos (v7, v8). 5. Complejidad adecuada: Aumentar excesivamente la complejidad del modelo puede hacer el entrenamiento inestable (v10_1, v10_2, v10_6). 6. Mecanismos eficientes: La atención multi-consulta (v10_4) y la fusión jerárquica (v10_5) proporcionan las ventajas de la eficiencia paramétrica y la integración gradual de características, respectivamente. 7. Importancia de la combinación óptima: Como se puede ver en v11, combinar adecuadamente mecanismos efectivos puede conducir a modelos de aprendizaje multimodal más estables y con mejor rendimiento.
Estos experimentos de eliminación son muy útiles para comprender el papel e importancia de cada componente en el aprendizaje multimodal. Además, proporcionan pautas importantes para diseñar nuevos modelos. Analizando sistemáticamente los cambios de rendimiento con la presencia o ausencia de ciertos mecanismos, se puede determinar qué elementos son efectivos para la fusión multimodal y qué combinaciones llevan a resultados óptimos.
Diseñando casos experimentales más sistemáticos y marcos de trabajo para proyectos, también se pueden realizar pruebas fluidas con modelos grandes y diversos mecanismos. Se espera que esto sea útil para la investigación.
En esta sección, examinaremos brevemente el transformer de visión (Vision Transformer, ViT), y sus extensiones ViT-22B y MAE, que han revolucionado el campo del procesamiento de imágenes.
En 2020, el equipo de Google Research presentó al mundo el ViT en el paper “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”. El ViT marcó el inicio de una nueva era basada en transformers en el procesamiento de imágenes, desplazando la hegemonía que las redes neuronales convolucionales (Convolutional Neural Network, CNN) habían mantenido durante mucho tiempo.
La idea central del ViT es simple: divide la imagen en varios fragmentos pequeños (parches, Patch) y trata cada parche como si fuera una palabra (token) en una oración de texto. De esta manera, la imagen se convierte en una secuencia de parches, que el transformer procesa como entrada.
En comparación con las CNN, el ViT presenta las siguientes diferencias clave:
Localidad vs. Globalidad: Las CNN utilizan filtros de convolución para enfocarse en extraer características locales de la imagen. Por otro lado, el ViT puede considerar directamente la relación entre cada parche y todos los demás parches de la imagen entera a través del mecanismo de atención (Attention Mechanism). Esto lo hace más ventajoso para comprender el contexto general de la imagen.
Estructura jerárquica vs. Estructura plana: Las CNN tienen una estructura jerárquica que abstrae gradualmente características a través de múltiples capas de convolución y agrupación (pooling). En contraste, el ViT divide la imagen en parches y los transforma todos en vectores de la misma dimensión para procesarlos a una única escala. Esta estructura plana facilita la implementación y optimización del modelo.
Dependencia de datos: Las CNN tienden a funcionar bien incluso con cantidades relativamente pequeñas de datos. Sin embargo, el ViT, al ser un modelo basado en transformers, requiere una cantidad suficiente de datos para desplegar su rendimiento óptimo. Un ViT preentrenado con conjuntos de datos a gran escala supera a las CNN en tareas de visión como clasificación de imágenes y detección de objetos.
La aparición del ViT cambió completamente la dirección de la investigación en procesamiento de imágenes. Desde el ViT, se han desarrollado numerosas investigaciones posteriores basadas en ideas como el embedding de parches de imagen, mecanismos de atención y preentrenamiento a gran escala.
El embedding de parches de imagen es la primera etapa del ViT, que convierte una imagen bidimensional en una secuencia unidimensional. En PyTorch, la clase torchvision.models.vision_transformer.PatchEmbed se encarga de esta tarea.
import torch
import torch.nn as nn
import torch.nn.functional as F
class PatchEmbed(nn.Module):
"""
Transforms a 2D image into a sequence of patch embeddings.
"""
def __init__(
self,
img_size: int = 224,
patch_size: int = 16,
in_chans: int = 3,
embed_dim: int = 768,
) -> None:
"""
Args:
img_size: The size of the input image (assuming a square image)
patch_size: The patch size (assuming square patches)
in_chans: The number of input image channels (e.g., 3 for RGB images)
embed_dim: The dimension of the patch embedding vector
"""
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) * (img_size // patch_size)
self.projection = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Transforms the input image into a sequence of patch embeddings.
Args:
x: Input image (shape: [batch_size, in_chans, img_size, img_size])
Returns:
Sequence of patch embeddings (shape: [batch_size, num_patches, embed_dim])
"""
x = self.projection(x) # [batch_size, embed_dim, num_patches_h, num_patches_w]
x = x.flatten(2) # [batch_size, embed_dim, num_patches]
x = x.transpose(1, 2) # [batch_size, num_patches, embed_dim]
return xLa parte más importante del método __init__ de la clase PatchEmbed es self.projection = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size). Esta única línea de código realiza tanto la división de parches de imagen como el embedding.
nn.Conv2d: Es una capa de PyTorch que realiza la operación de convolución 2D.in_chans: El número de canales de la imagen de entrada (3 para imágenes RGB).embed_dim: La dimensión del vector de embedding de salida (768 para el modelo ViT-Base).kernel_size=patch_size: Se establece el tamaño del filtro (núcleo) de convolución al mismo que el tamaño del parche.stride=patch_size: Se establece el intervalo (stride) con el que el filtro se mueve sobre la imagen al mismo que el tamaño del parche.Al establecer kernel_size y stride al mismo valor que patch_size, el filtro de convolución divide la imagen en parches no superpuestos, como si fuera un tablero de ajedrez. Cada filtro de convolución comprime la información de un parche en un vector de embedding.
En el método forward de la clase PatchEmbed, se realiza realmente el embedding de los parches de imagen a través de self.projection(x).
self.projection(x): Se aplica la operación Conv2d a la imagen de entrada x ([batch_size, in_chans, img_size, img_size]). La salida tiene forma [batch_size, embed_dim, num_patches_h, num_patches_w]. (num_patches_h y num_patches_w son los valores obtenidos al dividir la altura y el ancho de la imagen por el tamaño del parche).
x.flatten(2): Se aplana (flatten) la salida de Conv2d a una forma [batch_size, embed_dim, num_patches]. num_patches es el número total de parches (num_patches_h * num_patches_w).
x.transpose(1, 2): Se cambia la dimensión del tensor a [batch_size, num_patches, embed_dim], que es la forma requerida para la entrada del codificador transformer, donde cada vector de embedding de parche se trata como un elemento de la secuencia.
En resumen, la clase PatchEmbed divide la imagen en parches y realiza una transformación lineal (Linear Projection) para convertir cada parche en un vector de embed_dim dimensiones, creando así una secuencia que puede ser utilizada como entrada del codificador transformer.
ViT divide la imagen en parches y trata cada parche como si fuera una palabra de texto para su entrada al transformer. Sin embargo, el transformer no reconoce por sí mismo la información del orden de la secuencia de entrada. Por lo tanto, es necesario informarle al modelo a qué posición de la imagen corresponde cada parche. Esto se realiza mediante la codificación posicional (Positional Encoding).
En la clase VisionTransformer de PyTorch, se utilizan embeddings posicionales aprendibles (learnable). Es decir, durante el proceso de entrenamiento, se optimizan los vectores de embedding únicos que corresponden a la posición de cada parche.
class VisionTransformer(nn.Module):
def __init__(self, ..., num_patches, embed_dim, ...):
super().__init__()
# ...
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) # Class token
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim)) # Positional embedding
self.pos_drop = nn.Dropout(p=drop_rate)
# ...
def _pos_embed(self, x):
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1) # Prepend class token
x = x + self.pos_embed # Add positional embedding
return self.pos_drop(x)
def forward(self, x):
x = self.patch_embed(x) # Patch embedding
x = self._pos_embed(x) # Add positional embedding
# ... (Transformer Encoder etc.) ...Explicación del código
self.pos_embed (parámetro aprendible): Se define como un nn.Parameter y se actualiza durante el proceso de entrenamiento. Tiene una dimensión de (1, num_patches + 1, embed_dim).
num_patches + 1: Se añade 1 al número de parches para reservar espacio para un token de clase (class token) que tiene un rol especial.embed_dim: Tiene la misma dimensión que las embeddings de los parches.embed_dim._pos_embed:
self.cls_token al principio de la entrada x (secuencia de embeddings de parches). El cls_token se expande (expand) para replicarse según el tamaño del lote y se aplica uniformemente a todas las imágenes.self.pos_embed a las embeddings de los parches (y al token de clase). Según las reglas de broadcasting de PyTorch, cada vector de embedding de posición en self.pos_embed se suma automáticamente a todos los vectores de embedding de parches en la misma posición.forward: En el método forward, se convierte la imagen en embeddings de parches mediante self.patch_embed(x) y luego se llama a self._pos_embed(x) para añadir los embeddings posicionales.Resumen
ViT utiliza embeddings posicionales aprendibles para cada parche (y token de clase), que se suman a las embeddings de los parches para inyectar información de posición al modelo. Los embeddings posicionales se optimizan junto con otros pesos durante el entrenamiento del modelo, lo que permite representar la información de posición de manera óptima y adaptada a los datos.
ViT (Vision Transformer) es un modelo que procesa imágenes como si fueran texto para realizar tareas de visión, como la clasificación. En PyTorch, se puede utilizar el modelo ViT a través de la clase torchvision.models.VisionTransformer.
class VisionTransformer(nn.Module):
def __init__(self, ..., embed_dim, depth, num_heads, ...):
super().__init__()
self.patch_embed = PatchEmbed(...) # Image patch embedding
self.cls_token = nn.Parameter(...) # Class token
self.pos_embed = nn.Parameter(...) # Positional embedding
self.pos_drop = nn.Dropout(...)
self.blocks = nn.Sequential(*[
TransformerEncoderLayer(...) for _ in range(depth) # Transformer Encoder blocks
])
self.norm = nn.LayerNorm(embed_dim) # Layer Normalization
self.head = nn.Linear(embed_dim, num_classes) # Classification Head
def forward_features(self, x):
x = self.patch_embed(x) # 1. Patch embedding
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1) # 2. Prepend class token
x = x + self.pos_embed # 3. Add positional embedding
x = self.pos_drop(x)
x = self.blocks(x) # 4. Transformer Encoder
x = self.norm(x) # 5. LayerNorm
return x[:, 0] # 6. Return class token
def forward(self, x):
x = self.forward_features(x) # Feature extraction
x = self.head(x) # Classification
return xComponentes clave de ViT:
PatchEmbed (incrustación de parche): Divide la imagen en varios parches pequeños y convierte cada parche en un vector (incrustación) de dimensiones fijas. (Ver sección 10.5.2)cls_token (token de clase): Es un parámetro aprendible que se agrega al principio de la secuencia de incrustaciones de parche. Después de pasar por el codificador Transformer, este token de clase contiene información (características) representativa de toda la imagen y se utiliza para la clasificación final.pos_embed (incrustación posicional): Es un parámetro aprendible que indica la posición de cada parche (y del token de clase). Dado que el Transformer no puede reconocer por sí mismo el orden de la secuencia de entrada, se debe proporcionar información de posición explícitamente a través de las incrustaciones posicionales. (Ver sección 10.5.3)blocks (codificador Transformer): Está compuesto por varias capas TransformerEncoderLayer.
TransformerEncoderLayer: Es el bloque principal de ViT, que consta de Multi-Head Self-Attention y Feed-Forward Network (FFN).
norm (Normalización de Capa) : Se aplica normalización de capa a la salida del codificador Transformerhead (Cabeza de Clasificación): Es una capa fully-connected que toma como entrada el token de clase después de pasar por el codificador Transformer, y finalmente predice la clase de la imagen.Método forward (flujo general del procesamiento):
forward_features método:
self.patch_embed(x): Convierte la imagen de entrada en una secuencia de incrustaciones de parche.self.cls_token) al principio de la secuencia de incrustaciones de parche.self.pos_embed).self.blocks).self.norm).x[:, 0]).self.head(x): Pasa el token de clase devuelto por forward_features a través de la cabeza de clasificación para obtener el resultado final de predicción (clasificación).Resumen:
ViT divide la imagen en parches y los alimenta al codificador Transformer para extraer las características globales de toda la imagen. Durante este proceso, utiliza tokens de clase e incrustaciones posicionales para considerar tanto la información global de la imagen como la posición de los parches. Finalmente, utiliza el token de clase para clasificar la imagen.
Vamos a ver un ejemplo simple de cómo entrenar ViT con el conjunto de datos CIFAR-10. El código siguiente utiliza PyTorch para entrenar el modelo ViT y muestra la pérdida (loss) y precisión (accuracy) por época.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.models import vit_b_16 # Using vit_b_16 model as an example
from torch.utils.data import DataLoader
# Hyperparameter setup for a simple training run
num_epochs = 5
batch_size = 32
learning_rate = 1e-4
image_size = 224 # ViT input image size
num_classes = 10 # Number of classes in the CIFAR-10 dataset
# Use GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Data loading and preprocessing (using CIFAR-10 dataset)
transform = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # Normalize with CIFAR-10 statistics
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Create ViT model (not using pretrained weights)
model = vit_b_16(pretrained=False, num_classes=num_classes).to(device)
# Define loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=learning_rate)
# Training loop
for epoch in range(num_epochs):
model.train() # Set the model to training mode
running_loss = 0.0
correct_predictions = 0
total_samples = 0
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# Forward and backward passes
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Calculate statistics
running_loss += loss.item()
_, predicted = torch.max(outputs, 1) # Select the class with the highest probability
total_samples += labels.size(0)
correct_predictions += (predicted == labels).sum().item()
# Print every 100 batches.
# if (i + 1) % 100 == 0:
# print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
# Print epoch statistics
epoch_loss = running_loss / len(train_loader)
epoch_accuracy = correct_predictions / total_samples * 100
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {epoch_loss:.4f}, Accuracy: {epoch_accuracy:.2f}%')
print('Training finished!')100%|██████████| 170M/170M [00:21<00:00, 8.09MB/s]
/home/sean/anaconda3/envs/DL/lib/python3.10/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/sean/anaconda3/envs/DL/lib/python3.10/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=None`.
warnings.warn(msg)Epoch [1/5], Step [100/1563], Loss: 2.1349
Epoch [1/5], Step [200/1563], Loss: 1.8978
Epoch [1/5], Step [300/1563], Loss: 1.9483
Epoch [1/5], Step [400/1563], Loss: 2.0783
Epoch [1/5], Step [500/1563], Loss: 1.7614
Epoch [1/5], Step [600/1563], Loss: 1.8051
Epoch [1/5], Step [700/1563], Loss: 1.7448
Epoch [1/5], Step [800/1563], Loss: 1.8347
Epoch [1/5], Step [900/1563], Loss: 1.8127
Epoch [1/5], Step [1000/1563], Loss: 1.7755
Epoch [1/5], Step [1100/1563], Loss: 1.6506
Epoch [1/5], Step [1200/1563], Loss: 1.7523
Epoch [1/5], Step [1300/1563], Loss: 1.5987
Epoch [1/5], Step [1400/1563], Loss: 1.6078
Epoch [1/5], Step [1500/1563], Loss: 1.7110
Epoch [1/5], Loss: 1.8429, Accuracy: 29.66%
Epoch [2/5], Step [100/1563], Loss: 1.4902
Epoch [2/5], Step [200/1563], Loss: 1.5161
Epoch [2/5], Step [300/1563], Loss: 1.4563
Epoch [2/5], Step [400/1563], Loss: 1.5858
Epoch [2/5], Step [500/1563], Loss: 1.6702
Epoch [2/5], Step [600/1563], Loss: 1.5833
Epoch [2/5], Step [700/1563], Loss: 1.4790
Epoch [2/5], Step [800/1563], Loss: 1.6507
Epoch [2/5], Step [900/1563], Loss: 1.6017
Epoch [2/5], Step [1000/1563], Loss: 1.5102
Epoch [2/5], Step [1100/1563], Loss: 1.2946
Epoch [2/5], Step [1200/1563], Loss: 1.3225
Epoch [2/5], Step [1300/1563], Loss: 1.9922
Epoch [2/5], Step [1400/1563], Loss: 1.3685
Epoch [2/5], Step [1500/1563], Loss: 1.4852
Epoch [2/5], Loss: 1.5410, Accuracy: 42.69%
Epoch [3/5], Step [100/1563], Loss: 1.2692
Epoch [3/5], Step [200/1563], Loss: 1.1648
Epoch [3/5], Step [300/1563], Loss: 1.2412
Epoch [3/5], Step [400/1563], Loss: 1.6217
Epoch [3/5], Step [500/1563], Loss: 1.3776
Epoch [3/5], Step [600/1563], Loss: 1.2591
Epoch [3/5], Step [700/1563], Loss: 1.4333
Epoch [3/5], Step [800/1563], Loss: 1.3301
Epoch [3/5], Step [900/1563], Loss: 1.3536
Epoch [3/5], Step [1000/1563], Loss: 1.4488
Epoch [3/5], Step [1100/1563], Loss: 1.3179
Epoch [3/5], Step [1200/1563], Loss: 1.0684
Epoch [3/5], Step [1300/1563], Loss: 1.6526
Epoch [3/5], Step [1400/1563], Loss: 1.1815
Epoch [3/5], Step [1500/1563], Loss: 1.3683
Epoch [3/5], Loss: 1.3836, Accuracy: 49.23%
Epoch [4/5], Step [100/1563], Loss: 1.2601
Epoch [4/5], Step [200/1563], Loss: 1.3277
Epoch [4/5], Step [300/1563], Loss: 1.1337
Epoch [4/5], Step [400/1563], Loss: 1.2273
Epoch [4/5], Step [500/1563], Loss: 1.7351
Epoch [4/5], Step [600/1563], Loss: 1.3826
Epoch [4/5], Step [700/1563], Loss: 1.2639
Epoch [4/5], Step [800/1563], Loss: 1.5757
Epoch [4/5], Step [900/1563], Loss: 1.0702
Epoch [4/5], Step [1000/1563], Loss: 1.3986
Epoch [4/5], Step [1100/1563], Loss: 1.1105
Epoch [4/5], Step [1200/1563], Loss: 1.2621
Epoch [4/5], Step [1300/1563], Loss: 1.4261
Epoch [4/5], Step [1400/1563], Loss: 1.3028
Epoch [4/5], Step [1500/1563], Loss: 1.9051
Epoch [4/5], Loss: 1.2850, Accuracy: 52.98%
Epoch [5/5], Step [100/1563], Loss: 0.9517
Epoch [5/5], Step [200/1563], Loss: 0.9844
Epoch [5/5], Step [300/1563], Loss: 1.2391
Epoch [5/5], Step [400/1563], Loss: 1.3588
Epoch [5/5], Step [500/1563], Loss: 0.9441
Epoch [5/5], Step [600/1563], Loss: 1.1711
Epoch [5/5], Step [700/1563], Loss: 1.1687
Epoch [5/5], Step [800/1563], Loss: 1.0097
Epoch [5/5], Step [900/1563], Loss: 0.9899
Epoch [5/5], Step [1000/1563], Loss: 1.3289
Epoch [5/5], Step [1100/1563], Loss: 1.5510
Epoch [5/5], Step [1200/1563], Loss: 0.9139
Epoch [5/5], Step [1300/1563], Loss: 0.9221
Epoch [5/5], Step [1400/1563], Loss: 1.3378
Epoch [5/5], Step [1500/1563], Loss: 1.1785
Epoch [5/5], Loss: 1.2116, Accuracy: 55.78%
Training finished!Este código es un ejemplo sencillo que muestra cómo funciona el modelo ViT. El ViT real, después de ser pre-entrenado (pre-training) en conjuntos de datos a gran escala como ImageNet, se utiliza ajustándolo finamente (fine-tuning) para tareas específicas (por ejemplo, clasificación CIFAR-10), lo que resulta en un rendimiento significativamente mejor. Aquí solo verificamos si es posible realizar el entrenamiento.
Significado e Impacto del ViT
El ViT ha causado una gran resonancia en el campo de la visión por computadora al demostrar un rendimiento superior a las CNN en tareas de clasificación de imágenes. En particular, cuando se pre-entrena con conjuntos de datos a gran escala como JFT-300M, que contiene más de 300 millones de imágenes, muestra su verdadero valor. Esto ha arrojado dos importantes implicaciones:
Escalabilidad: El ViT ha demostrado una excelente escalabilidad al mejorar constantemente su rendimiento a medida que el tamaño del conjunto de datos aumenta. Esto contrasta con la tendencia de los modelos basados en CNN, donde el rendimiento puede estancarse o incluso empeorar cuando se utilizan conjuntos de datos más grandes. Esta característica del ViT abre la posibilidad de construir modelos de visión aún más potentes al aprovechar mayores cantidades de datos.
Versatilidad del Transformer: El ViT ha demostrado que la arquitectura del transformer, ampliamente utilizada en el procesamiento del lenguaje natural (NLP), también puede ser efectiva para el procesamiento de imágenes. Esto ha servido como un catalizador para la investigación de modelos multimodales capaces de manejar diferentes modalidades (una arquitectura) como texto, imágenes y audio.
El éxito del ViT se convirtió en una base importante para el desarrollo posterior de modelos multimodales como CLIP (Contrastive Language-Image Pre-training). CLIP combina el codificador de imágenes de ViT con un codificador de texto basado en transformer para aprender a representar imágenes y texto en un espacio integrado. Esto ha permitido diversas aplicaciones, como la generación de descripciones textuales de imágenes o la búsqueda de imágenes basada en descripciones textuales.
Traducción:
El texto original no se proporcionó para realizar la traducción. Por favor, proporcione el texto en coreano que desea traducir al español.
Google Research propuso y entrenó el ViT-22B, que ha causado un gran impacto en el campo de la visión por computadora al superar el rendimiento de las CNN en la clasificación de imágenes. El ViT-22B demostró que la expansión del tamaño del modelo y los datos es uno de los factores clave para mejorar el rendimiento. Con un tamaño abrumador de 22 mil millones de parámetros y entrenado con un conjunto de datos a gran escala compuesto por miles de millones de imágenes, el ViT-22B logró niveles de rendimiento que antes eran difíciles de imaginar, abriendo nuevas perspectivas en la IA de visión.
Origen: Reglas de Escalabilidad y Éxito de los Modelos de Lenguaje Grandes
La aparición del ViT-22B está estrechamente relacionada con el éxito asombroso que han demostrado los modelos de lenguaje grandes (LLM) en el campo del procesamiento de lenguaje natural (NLP). Se ha mostrado que LLM como GPT-3 siguen la regla de escalabilidad (scaling law), según la cual el rendimiento mejora consistentemente a medida que se aumenta el tamaño del modelo (número de parámetros) y la cantidad de datos. Esta tendencia propagó la creencia de que “lo más grande es lo mejor” y llevó a intentos similares en el campo de la visión.
Dado que ViT está basado en una arquitectura de transformador, fue fácil aplicar las estrategias de escalabilidad probadas en los LLM. Debido a su capacidad para tratar parches de imágenes como tokens de texto, se pudo aumentar el número de parámetros y utilizar más datos para entrenar sin realizar cambios sustanciales en la estructura del modelo.
Estructura y Características del ViT-22B
El ViT-22B sigue básicamente la arquitectura de ViT, pero se distingue por su escala.
Modelo de gran tamaño: Con 22 mil millones de parámetros, el ViT-22B es significativamente más grande que el ViT-Base (86 millones), ViT-Large (307 millones) y ViT-Huge (632 millones). Esto significa que el modelo puede capturar características de imagen más complejas y sutiles e incorporar un mayor conocimiento.
Conjunto de datos a gran escala: El ViT-22B se entrenó con un conjunto de datos privado compuesto por más de mil millones de imágenes (como JFT-4B). Estos grandes conjuntos de datos son esenciales para maximizar el rendimiento general del modelo y para aprender una variedad de distribuciones de imágenes.
Rendimiento mejorado: El ViT-22B registró un rendimiento sobresaliente (SOTA, State-Of-The-Art) en comparación con otros modelos en tareas de clasificación de imágenes. Esto demuestra claramente el impacto positivo del tamaño del modelo y la cantidad de datos en el rendimiento.
Dificultades y Implicaciones del Entrenamiento del ViT-22B
Entrenar un modelo a gran escala como el ViT-22B es casi imposible en entornos de investigación comunes. Se requieren cientos o miles de GPU o TPU costosas, y el tiempo de entrenamiento puede durar desde semanas hasta meses. Además, la infraestructura para almacenar y procesar cantidades enormes de datos también representa un desafío significativo.
Aunque la aparición del ViT-22B demostró la escalabilidad de la arquitectura de ViT, también plantea preocupaciones sobre la eficiencia. A medida que el tamaño del modelo aumenta, el rendimiento mejora, pero los recursos computacionales y el consumo de energía necesarios para entrenamiento e inferencia crecen exponencialmente. Por lo tanto, se espera que futuras investigaciones se dirijan hacia mejorar la eficiencia mientras se mantiene el rendimiento del modelo.
Meta AI (Facebook AI Research, FAIR) equipo propuso MAE (Masked Autoencoder), un método de aprendizaje autónomo (self-supervised learning) que utiliza conjuntos de datos de imágenes a gran escala sin etiquetas para aprender representaciones de imagen potentes. Basado en ViT, el MAE oculta una parte considerable de la imagen de manera aleatoria (masking) y entrena al modelo para reconstruir las partes ocultas. El MAE v3 es la versión más reciente del MAE, que ha mejorado aún más su rendimiento y eficiencia con varias mejoras.
Funcionamiento de MAE
La idea clave detrás de MAE es entrenar a un modelo para comprender e iniciar una imagen completa utilizando solo parte de la información, similar a cómo las personas resuelven problemas de “llenado de espacios en blanco”.
Ocultación aleatoria de imágenes de entrada: Se oculta una parte sustancial (por ejemplo, el 75%) de la imagen de entrada de manera aleatoria. Esta ocultación se realiza a nivel de parches de imagen.
Codificación (Encoding): Solo los parches visibles se introducen en el codificador ViT para extraer vectores de características.
Decodificación (Decoding): Se utiliza la salida del codificador (características de los parches visibles) y la información sobre los parches ocultos para reconstruir la imagen original. En este proceso, el decodificador se compone de bloques Transformer ligeros para aumentar la eficiencia computacional.
Pérdida de reconstrucción (Reconstruction Loss): Se calcula la diferencia a nivel de píxeles entre la imagen reconstruida y la imagen original (por ejemplo, Error Cuadrático Medio, MSE) y se entrena al modelo (codificador y decodificador) para minimizar esta diferencia.
Mejoras estructurales en MAE v3
MAE v3 ha logrado un mejor rendimiento y eficiencia en comparación con las versiones anteriores gracias a las siguientes mejoras importantes:
Estrategia de ocultación mejorada: A diferencia del MAE inicial, que simplemente ocultaba parches de manera aleatoria, el MAE v3 utiliza estrategias más sofisticadas de ocultación. Por ejemplo, puede preservar mejor las áreas significativas de la imagen (como los bordes de objetos) o aplicar la ocultación a parches de tamaños diversos.
Estructura optimizada del codificador-decodificador
Escalabilidad: La escala del modelo ha sido ampliada desde ViT-L hasta ViT-H, permitiendo un mayor uso de datos y mejora en el rendimiento.
Ventajas e importancia de MAE
MAE es destacado en el campo de aprendizaje autónomo por las siguientes ventajas:
Aprendizaje sin etiquetas necesarias: MAE puede realizar el pre-entrenamiento utilizando conjuntos de datos de imágenes a gran escala sin etiquetas, lo que reduce los costos y tiempo asociados con la creación manual de etiquetas y permite el uso de más datos.
Aprendizaje de representaciones potentes: A través del proceso de reconstrucción de una imagen con partes ocultas, MAE desarrolla habilidades para comprender la estructura, significado y contexto de las imágenes. Estas habilidades son útiles en diversas tareas downstream como clasificación de imágenes, detección de objetos y segmentación.
Facilidad de transferencia (Transfer Learning): Los modelos pre-entrenados con MAE pueden ser finetuneados para varias tareas, lo que permite obtener buenos resultados incluso en tareas con escasez de etiquetas.
Conclusión MAE presentó un método efectivo para aprender representaciones de imágenes poderosas sin etiquetas a través de la idea intuitiva de “llenar los espacios en blanco”. MAE v3 mejora aún más estas ventajas de MAE, logrando un rendimiento y eficiencia superiores y liderando el avance de la investigación de aprendizaje automático.
En 2021, OpenAI presentó el modelo CLIP (Contrastive Language-Image Pre-training) en el artículo “Learning Transferable Visual Models From Natural Language Supervision”. CLIP ha traído un desarrollo revolucionario al campo del aprendizaje multimodal al aprender a representar dos modalidades diferentes, imágenes y texto, en un espacio compartido.
El núcleo de CLIP es la estructura de codificador dual, compuesta por codificador de imagen (Image Encoder) y codificador de texto (Text Encoder), dos codificadores independientes.
Ambos codificadores se entrenan a través de aprendizaje contrastivo (contrastive learning).
El núcleo del entrenamiento de CLIP: Aprendizaje contrastivo (Contrastive Learning)
El núcleo del entrenamiento de CLIP es el aprendizaje contrastivo utilizando un conjunto de datos a gran escala de pares imagen-texto.
Ejemplo de código
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class CLIP(nn.Module):
def __init__(self, image_encoder, text_encoder, embed_dim):
super().__init__()
self.image_encoder = image_encoder
self.text_encoder = text_encoder
self.image_projection = nn.Linear(image_encoder.output_dim, embed_dim)
self.text_projection = nn.Linear(text_encoder.output_dim, embed_dim)
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07)) # Learnable scale parameter
def forward(self, images, texts):
# 1. Image encoding
image_features = self.image_encoder(images) # [batch_size, image_encoder.output_dim]
image_embeddings = self.image_projection(image_features) # [batch_size, embed_dim]
image_embeddings = F.normalize(image_embeddings, dim=-1) # L2 normalization
# 2. Text encoding
text_features = self.text_encoder(texts) # [batch_size, text_encoder.output_dim]
text_embeddings = self.text_projection(text_features) # [batch_size, embed_dim]
text_embeddings = F.normalize(text_embeddings, dim=-1) # L2 normalization
# 3. Similarity calculation
logits_per_image = self.logit_scale.exp() * image_embeddings @ text_embeddings.t() # [batch_size, batch_size]
logits_per_text = logits_per_image.t() # [batch_size, batch_size]
return logits_per_image, logits_per_text
def contrastive_loss(logits_per_image, logits_per_text):
"""
Calculates the Contrastive Loss
"""
batch_size = logits_per_image.shape[0]
labels = torch.arange(batch_size).to(logits_per_image.device) # Correct labels (diagonal: same pair)
loss_i = F.cross_entropy(logits_per_image, labels) # Loss based on image
loss_t = F.cross_entropy(logits_per_text, labels) # Loss based on text
return (loss_i + loss_t) / 2 # Average lossEl codificador de imagen de CLIP toma una imagen como entrada y la convierte en un vector de embedding de dimensión fija. En el artículo original de CLIP, se experimentó tanto con ResNet como con ViT (Vision Transformer).
Los resultados experimentales mostraron que el codificador basado en ViT tuvo un mejor rendimiento que el basado en ResNet. En particular, a medida que aumentaban el tamaño del modelo y de los datos, la mejora en el rendimiento de ViT era aún mayor.
El codificador de texto de CLIP toma una descripción de texto como entrada y la convierte en un vector de embedding de la misma dimensión que el del codificador de imagen. En el artículo original de CLIP, se utilizó un codificador de texto basado en Transformer.
Una de las características más destacadas de CLIP es su capacidad de transferencia cero-disparo (zero-shot transfer), que permite rendimientos excelentes en varias tareas de clasificación de imágenes sin ajuste fino adicional.
Razón por la cual es posible la transferencia cero-disparo
Durante el proceso de aprendizaje contrastivo con un conjunto de datos a gran escala de pares imagen-texto, CLIP aprende a representar imágenes y texto en el mismo espacio semántico. En otras palabras, CLIP adquiere la capacidad de comprender las relaciones semánticas entre imágenes y texto.
Proceso de clasificación cero-disparo
Se preparan descripciones de texto para las clases a clasificar. Por ejemplo, en el caso del conjunto de datos CIFAR-10, se prepararían descripciones de texto como “una foto de un gato”, “una foto de un perro”, …, “una foto de un camión”.
Se utilizan los codificadores de texto para embeber cada descripción de texto.
Se utiliza el codificador de imagen para embeber la imagen dada.
Se calcula la similitud (por ejemplo, similitud coseno) entre el embedding de la imagen y cada embedding de texto.
Se selecciona como clase predicha de la imagen aquella que corresponde a la descripción de texto con la mayor similitud.
Significado de la transferencia cero-disparo
La transferencia cero-disparo significa que el modelo puede aplicarse inmediatamente a nuevas clases o tareas que no vio durante el proceso de entrenamiento, sin necesidad de un ajuste fino adicional. Esto contrasta con los métodos de aprendizaje supervisado tradicionales, que requieren datos etiquetados específicos para una tarea en particular.
La clave de la transferencia cero-disparo es la flexibilidad. Por ejemplo, aunque se use solo datos de las clases “gato” y “perro” para entrenar un modelo de clasificación de imágenes, si se proporciona una imagen de una clase no vista como “jirafa” o “elefante”, el modelo puede clasificarla correctamente con descripciones naturales como “foto de jirafa” o “foto de elefante”. De esta manera, la transferencia cero-disparo permite maximizar la capacidad de generalización del modelo en situaciones donde no hay datos disponibles para nuevas clases o tareas. Además, la transferencia de cero disparos (zero-shot) proporciona versatilidad. No solo se aplica a la clasificación de imágenes, sino también a tareas multimodales variadas como búsqueda de imágenes, generación de descripciones de imágenes, detección de objetos, y respuestas visuales a preguntas (Visual Question Answering, VQA). Por ejemplo, en un sistema de búsqueda de imágenes, al ingresar una consulta de texto como “coche deportivo rojo”, el modelo puede encontrar imágenes que correspondan a “coche deportivo rojo” en la base de datos. Esto es posible porque el modelo entiende las relaciones semánticas entre imágenes y texto. De esta manera, poder utilizar un solo modelo para diversas tareas ahorra tiempo y recursos, y contribuye significativamente al aumento de la utilidad de los sistemas de inteligencia artificial.
Impacto de CLIP
CLIP demostró nuevas posibilidades en el aprendizaje multimodal a través de su capacidad de transferencia de cero disparos. Desde entonces, se han llevado a cabo numerosas investigaciones posteriores basadas en las ideas de CLIP, influyendo enormemente en el desarrollo de modelos de generación de imágenes como DALL-E y Stable Diffusion, así como en la creación de modelos multimodales a gran escala como GPT-4V.
Contrastive Learning es un enfoque poderoso para aprender representaciones a partir de datos no etiquetados. En particular, ha demostrado excelentes resultados en el aprendizaje multimodal, que conecta modalidades diferentes como imágenes y texto. En esta inmersión profunda, analizaremos detalladamente los principios básicos de Contrastive Learning, sus diversos enfoques, y el modelo innovador CLIP (Contrastive Language-Image Pre-training), que conecta imágenes y texto basándose en Contrastive Learning.
La idea central del Contrastive Learning es aprender representaciones que hagan que los pares de muestras similares (pares positivos) estén cerca en el espacio de embedding, mientras que los pares de muestras no similares (pares negativos) estén lejos.
El Contrastive Learning generalmente sigue los siguientes pasos.
Se han propuesto varias funciones de pérdida contrastivas, entre las cuales se encuentran:
InfoNCE Loss (Estimación Contrastiva del Ruido): Tiene una forma similar a la función de pérdida de entropía cruzada y maximiza la probabilidad softmax para los pares positivos.
\(L = -\log \frac{\exp(\text{sim}(z_i, z_j) / \tau)}{\sum_{k=1}^{2N} \mathbb{1}_{[k \neq i]} \exp(\text{sim}(z_i, z_k) / \tau)}\)
NT-Xent Loss (Entropía Cruzada Escalada por Temperatura Normalizada): Es una variante de InfoNCE Loss, propuesta en el paper SimCLR.
Triplet Loss: Utiliza muestras Anchor, Positiva y Negativa para que la distancia entre el Anchor y la muestra positiva sea menor que la distancia entre el Anchor y la muestra negativa.
\(L = \max(0, d(a, p) - d(a, n) + m)\)
\(a\): Ancla
\(p\): Ejemplo positivo
\(n\): Ejemplo negativo
\(d(\cdot, \cdot)\): Función de distancia (por ejemplo, distancia euclidiana)
\(m\): Margen (determina cuánto se deben separar las distancias)
CLIP es un modelo desarrollado por OpenAI que utiliza el aprendizaje contrastivo para aprender representaciones multimodales potentes que conectan imágenes y texto.
El Aprendizaje Contrastivo es un enfoque efectivo para aprender representaciones poderosas utilizando datos sin etiquetas. En particular, CLIP ha aplicado con éxito el Aprendizaje Contrastivo al aprendizaje multimodal, abriendo nuevas perspectivas para conectar imágenes y texto. Se espera que tanto el Aprendizaje Contrastivo como CLIP sigan siendo utilizados en diversos campos en el futuro.
Referencias: * Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020). Un marco simple para el aprendizaje contrastivo de representaciones visuales. Conferencia internacional sobre aprendizaje automático. PMLR. * Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021). Aprendizaje de modelos visuales transferibles a partir de la supervisión del lenguaje natural. Conferencia Internacional sobre Aprendizaje Automático. PMLR. * He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast para el aprendizaje no supervisado de representaciones visuales. En Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9729-9738). * Grill, J. B., Strub, F., Altché, F., Tallec, C., Richemond, P., Buchatskaya, E., … & Valko, M. (2020). Bootstrap your own latent-un nuevo enfoque para el aprendizaje supervisado por sí mismo. Advances in neural information processing systems, 33, 21271-21284.
Problemas Básicos
Problemas Aplicados
blip-image-captioning-base).Problemas Avanzados
Estructura del modelo VQA:
graph LR
subgraph Modelo VQA
A[Imagen] --> B(Codificador de Imagen - CNN)
C[Texto de Pregunta] --> D(Codificador de Texto - RNN/Transformer)
B --> E(Módulo de Fusión)
D --> E
E --> F(Decodificador - RNN/Transformer)
F --> G(Respuesta)
endMétodo de aprendizaje y ventajas de CLIP:
Código de Hugging Face Transformers para Generación de Descripciones de Imágenes:
from transformers import pipeline
captioner = pipeline("image-to-text", model="nlpconnect/vit-gpt2-image-captioning") # o "blip-image-captioning-base"
image_path = "path/to/your/image.jpg" # ruta del archivo de imagen
caption = captioner(image_path)[0]['generated_text']
print(caption)Métodos de Fusión Multimodal:
Atención Cross-Modal:
Modelos de Generación de Imágenes Basados en Texto (DALL-E, Stable Diffusion, etc.):
CLIP (Learning Transferable Visual Models From Natural Language Supervision): el artículo original de CLIP, un método de aprendizaje de representaciones multimodales que conecta imágenes y texto. https://arxiv.org/abs/2103.00020
ViT (An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale): el artículo original de ViT, que demostró un rendimiento sobresaliente en la clasificación de imágenes utilizando únicamente la estructura de Transformer sin CNN. https://arxiv.org/abs/2010.11929
DALL-E (Zero-Shot Text-to-Image Generation): el artículo del modelo DALL-E, que genera imágenes basadas en descripciones de texto. https://arxiv.org/abs/2102.12092
MAE (Masked Autoencoders Are Scalable Vision Learners): el artículo de MAE, que aprende representaciones visuales ocultando y reconstruyendo partes de las imágenes. https://arxiv.org/abs/2111.06377
Visual Question Answering (VQA): uno de los primeros estudios de VQA, que presenta el conjunto de datos VQA y modelos base. https://arxiv.org/abs/1505.00468
Show, Attend and Tell (Neural Image Caption Generation with Visual Attention): el artículo que introdujo el mecanismo de atención en la generación de subtítulos de imágenes. https://arxiv.org/abs/1502.03044
Multimodal Machine Learning: A Survey and Taxonomy: un artículo de revisión exhaustivo sobre aprendizaje multimodal. https://arxiv.org/abs/1705.09406
A Tutorial on Multimodal Deep Learning, Jiquan Ngiam: tutorial de aprendizaje profundo multimodal presentado en NeurIPS 2011 (video). https://www.youtube.com/watch?v=cR_ACqfF-bY&list=PL_45CaSOtPzL-HWxMcnr02KvmP9Gq-xdb
CMU Multimodal Machine Learning Course (11-777, Spring 2023), Louis-Philippe Morency: Material de curso de aprendizaje automático multimodal de la Universidad Carnegie Mellon. https://cmu-multicomp-lab.github.io/mmml-course/spring2023/
A Comprehensive Survey on Deep Multimodal Learning: Artículo de revisión sobre aprendizaje profundo multimodal del año 2022. https://arxiv.org/abs/2204.11984
arXiv: Búsqueda de artículos de investigación más recientes sobre aprendizaje multimodal. Utilice palabras clave como “multimodal learning”, “visión-lenguaje”. https://arxiv.org/
Hugging Face Transformers Multimodal Documentation: Documentación de modelos multimodales de la biblioteca Hugging Face Transformers. https://huggingface.co/docs/transformers/main/en/model_doc/auto#multimodal-models